本文将探讨大模型的在下游任务种的未来前景。
下游任务探索

金融——银行业:1)前台电话营销、智能客服;2)小微信贷封控(资料来源:ChatGPT 只是客服机器人?上海多家银行早有实践:AI 已用于小微信贷风控_上观新闻 (jfdaily.com));3)语音电话催收。
金融——证券业:1)证券投研报告生成;2)投行招股书撰写;3)炒股软件。
金融——保险业:1)优化保费计算模型;2)智能理赔。
电力:1)虚拟电厂,调节波峰波谷;2)智能巡检。
工业:1)工业互联网(资料来源:长三角首个 AI+工业互联网产业基地启动 百度文心一言来了 (baidu.com))。2)与硬件结合,实现更智能的机器人应用。医疗:1)ai线上问诊;2)ai读片、读报告。
旅游:1)语音订票、订房;2)行程规划。
办公:1)自动生成报告、演示文稿、excel 等;2)与在线会议结合生成会议要点、会议记录。
线下商业:1)智能前台;2)ai 试衣;3)客流分析。
家居、汽车等:提供智能语音交互、个人助手。
安全:优化安全模型,提升网安管理效率。
医保:1)AI 辅助医保控费;2)辅助商保产品设计与理赔。
航天:中科星图、航天宏图等。
大数据分析:星环科技等。
教育:科大讯飞、佳发教育、捷安高科等。
商业智能(BI)——数据分析
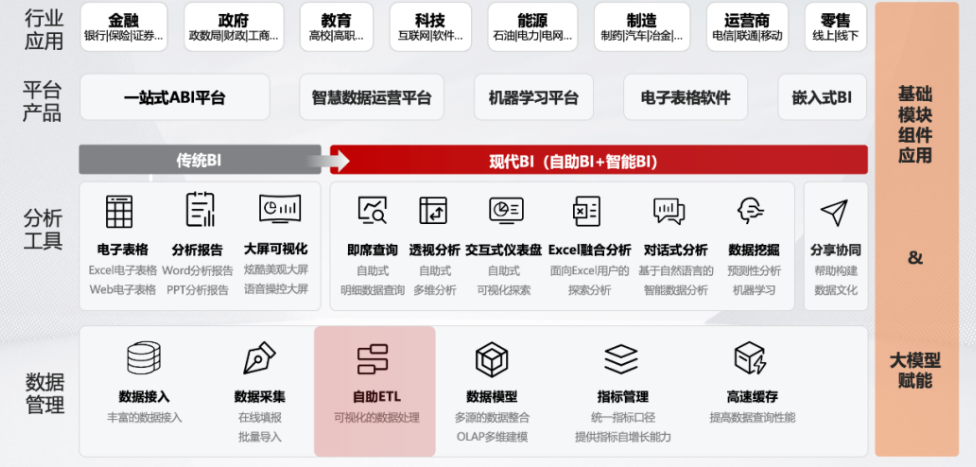
在数据处理层面,大模型可以帮助传统的ETL过程简化难度,提高实时交互效率。在数据分析层面,大模型可以替代拖拽交互方式,让业务用户用更简单、更高效的方式以自然语言形式与底层数据交互,来构建需要的报表和看板。在行业应用层面,大模型可以真正发挥对行业知识的理解能力,与具体数据结合,形成具针对客户、特定项目、指标体系的输出,再加上数据准备,可能直接输出标准化的项目成果。
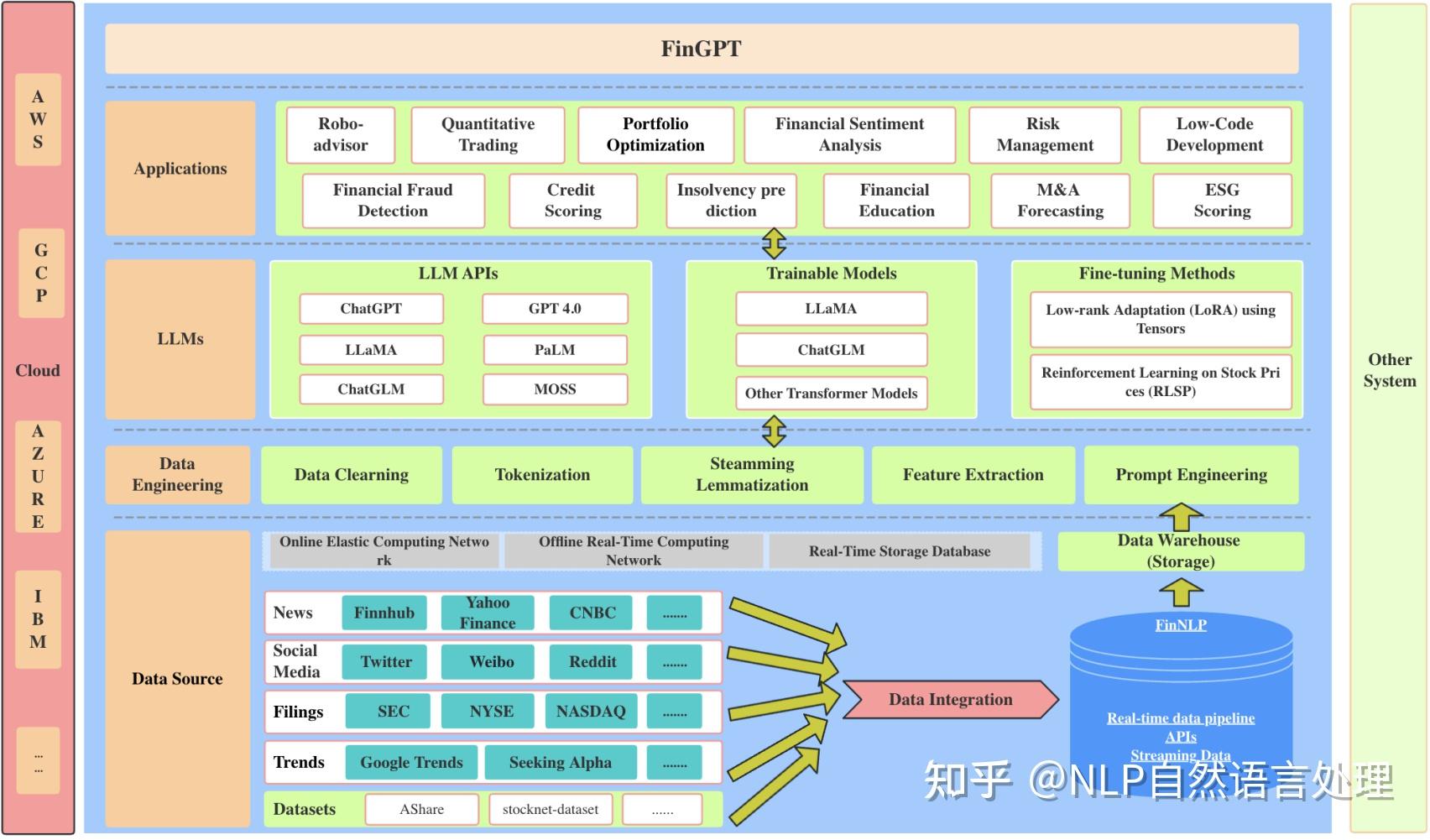
金融分析
开源的大语言模型框架FinGPT,专门用于金融领域,它采用以数据为中心的方法,为研究人员提供了可访问和资源来开发自己FinLLMs。该框架可用在智能投顾、情绪分析、量化交易、风险管理、破产预测、金融教育培训等方面。
多模态商业化
图像编辑:指的是根据用户的输入需求对图像进行编辑,被广泛地应用到多媒体领域中。
图像描述:指的是给定一个图像,用自然语言描述出图像中的主要内容。
图像检索:指的是按照用户的需求检索图像,目前这类应用比较普遍,但是传统方法的效果不是特别理想,多模态大模型可以有效地提升这类应用的效果。
图像问答:指的是用户输入图像,然后对输入的内容进行提问,多模态大模型就可以智能地根据图像中蕴含的语义信息输出自然语言答案,还可以进行多轮对话。
图像理解和推理:指的是理解输入的图像想要表达的内容,然后进行高级推理,比如找到与图像表达内容相近的图像或者解决更高级的图形推理数学问题。
语音生成:指的是根据用户各种类型的输入(文本、图像等)生成符合期望的语音。语音生成技术在多媒体素材创作中有着广泛的应用。
语音编辑:指的是根据用户各种类型的输入对语音进行编辑,也被广泛地应用到多媒体领域中。
语音描述:指的是给定语音,用自然语言描述出语音中的主要内容。
语音检索:指的是按照用户的需求检索语音。
语音问答:指的是用户输入语音,然后对输入的内容进行提问,多模态大模型就可以智能地根据语音中蕴含的语义信息输出自然语言答案,还可以进行多轮对话。
语音理解和推理:指的是理解输入的语音想要表达的内容,然后进行高级推理,比如找到与语音表达内容相近的语音或者将语音转化为文本、图像或视频。
视频生成:指的是根据用户各种类型的输入(文本、语音、图像等)生成符合期望的视频。视频生成技术在多媒体素材创作中有着广泛的应用。
视频编辑:指的是根据用户各种类型的输入对视频进行编辑,比如分割、修改、合并等,也被广泛地应用到多媒体领域中。
视频描述:指的是给定视频,用自然语言描述出视频中的主要内容。
视频检索:指的是按照用户的需求检索视频。随着短视频的兴起,目前该领域十分火爆,但是传统的深度学习技术在视频检索时精准度不够,多模态大模型有助于进一步提升效果,也有助于推进AI在该领域中更广泛的应用。
视频问答:指的是用户输入视频,然后对输入的内容进行提问,多模态大模型就可以智能地根据视频中蕴含的语义信息输出自然语言答案或者语音答案,还可以进行多轮对话。
视频理解和推理:指的是理解输入的视频想要表达的内容,然后进行高级推理。比如,识别视频中的破绽,或者将多个视频的语义融合,生成更复杂的视频。
多模态翻译:指的是给定多媒体素材(文本、语音、视频等),能够对里面的内容进行翻译,比如实现不同语言之间的翻译、添加字幕等。
情绪识别:指的是给定多媒体素材,判断该素材中实体的情绪,比如给定一张图片,判断图片中的实体(比如人、动物等)的情绪。
多模态目标检测:指的是给定多媒体素材,比如一段文本和一段视频,然后在视频中能够智能地对文本描述的目标进行检测,被广泛地应用于机器视觉和自动驾驶领域。
多模态目标识别:指的是给定多媒体素材,比如一段文本和一段视频,然后在视频中能够智能地对文本描述的目标进行精准识别,被广泛地应用于机器视觉和自动驾驶领域。
多模态目标追踪:指的是给定多媒体素材,比如一段文本和一段视频,然后在视频中能够智能地对文本描述的目标进行追踪,被广泛地应用于机器视觉和自动驾驶领域。
多模态路径规划:指的是根据用户的需求规划最佳路径,被广泛地应用于导航、机器视觉和自动驾驶领域。
多模态对话:指的是更有效地实现人机对话及机器和机器对话,被广泛地应用于机器视觉和自动驾驶领域。
巡检:指的是机器人根据摄像头拍到的信息,同时根据输入的任务(文本或者语音)能够完成巡检任务。
数字人:指的是根据文本和图片等信息,构建企业或个人的数字人,然后让数字人通过语音或视频等多媒体形式生动地进行内容输出。
艺术创作:指的是完成文艺创作,比如写诗、作图等多媒体任务。
智能助手:指的是企业或者个人的助手,可以协助完成各类复杂的工作和任务,比如多轮问答、文案生成、PPT撰写和数字人生成等。
生物识别:指的是根据各类信息,比如图像、视网膜、指纹、语音和行为特征等,精准地进行生物识别。生物识别比目前传统的单一功能识别(比如图像身份识别或者语音身份识别)的效果好得多。
上述多模态大模型的30个基础应用可以组合应用到更复杂的场景或行业中。比如,在无人驾驶领域中,可能需要涉及多模态目标识别、多模态目标检测、多模态目标追踪、多模态对话、情绪识别等多个基础应用的融合。
实际案例