Langchain是一种基于本地文库与大模型的问答架构。
Langchain
Langchain原理介绍
LangChian 可以将 LLM 模型、向量数据库、交互层 Prompt、外部知识、外部工具整合到一起,进而可以自由构建 LLM 应用。LangChian 之所以称为Langchain,是因为他像一条链子一样串联起本地文库、用户需求和大模型。
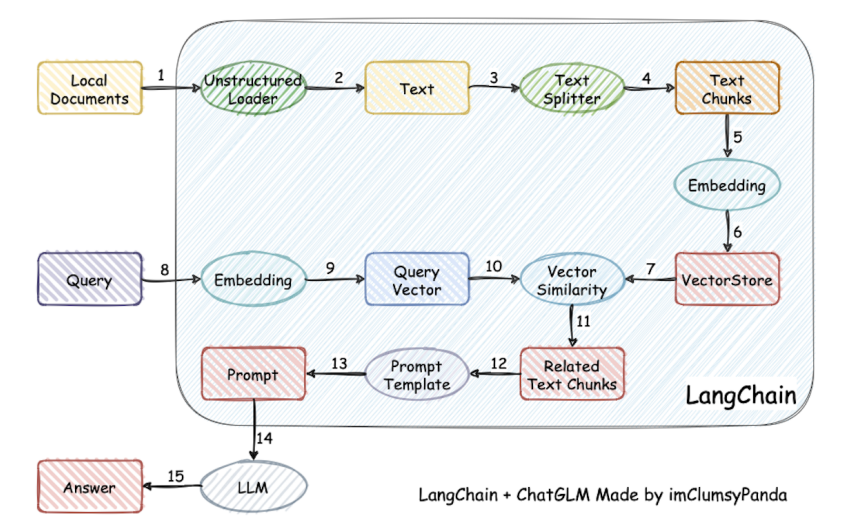
数据接入层
打通外部数据的管道,包含文档加载,文档转换,文本嵌入,向量存储几个环节。就是把大量的数据组合起来,让LLM能够尽可能少地消耗计算力就能轻松地引用。它的工作原理是把一个大的数据源,比如一个50页的PDF文件,分成一块一块的,然后把它们嵌入到一个向量存储(Vector Store)里。小白入门大模型:LangChain - 知乎 (zhihu.com)LangChain:一个让你的LLM变得更强大的开源框架 - 知乎 (zhihu.com)
Step 1:文档加载
重点包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的加载引擎)几种常用格式的内容解析。
Step 2:文档拆分
这种方式会将语义最相关的文本片段放在一起。Langchain提供了多种文本分割器,包括CharacterTextSplitter(),MarkdownHeaderTextSplitter(),RecursiveCharacterTextSplitter()等。
- RecursiveCharacterTextSplitter():按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter():按字符来分割文本。
- MarkdownHeaderTextSplitter():基于指定的标题来分割markdown 文件。
- TokenTextSplitter():按token来分割文本。
- SentenceTransformersTokenTextSplitter() : 按token来分割文本
- Language() - 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter():使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter() - 使用 Spacy按句子的切割文本。
Langchain使用之 - 文本分割Splitter_recursivecharactertextsplitter-CSDN博客让Langchain与你的数据对话(一):数据加载与分割 - 知乎 (zhihu.com)
示例:使用RecursiveCharacterTextSplitter对一段文字进行分割。
1 | from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter |
结果:分割后,得到的结果如下所示,每一段chunk尽量和chunk_size贴近,每个chunk之间也有overlap。RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级[“\n\n”, “\n”, “ “, “”]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置.在项目中也推荐使用RecursiveCharacterTextSplitter来进行分割。
Step 3:文本嵌入(embedding,数据转向量)
文本嵌入原理:向量是一个有方向和长度的量,可以用数学中的坐标来表示。例如,可以用二维坐标系中的向量表示一个平面上的点,也可以用三维坐标系中的向量表示一个空间中的点。在机器学习中,向量通常用于表示数据的特征。而文本嵌入是一种将文本这种离散数据映射到连续向量空间的方法,嵌入技术可以将高维的离散数据降维到低维的连续空间中,并保留数据之间的语义关系,从而方便进行机器学习和深度学习的任务。
文本嵌入算法:是指将文本数据转化为向量表示的具体算法,通常包括以下几个步骤:
- 分词:将文本划分成一个个单词或短语。
- 构建词汇表:将分词后的单词或短语建立词汇表,并为每个单词或短语赋予一个唯一的编号。
- 计算词嵌入:使用预训练的模型或自行训练的模型,将每个单词或短语映射到向量空间中。
- 计算文本嵌入:将文本中每个单词或短语的向量表示取平均或加权平均,得到整个文本的向量表示。
常见的文本嵌入算法包括 Word2Vec、GloVe、FastText 等。这些算法通过预训练或自行训练的方式,将单词或短语映射到低维向量空间中,从而能够在计算机中方便地处理文本数据。
文本嵌入常用于以下场合:
- 搜索(结果按与查询字符串的相关性排序)
- 聚类(其中文本字符串按相似性分组)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别出相关性很小的异常值)
- 多样性测量(分析相似性分布)
- 分类(其中文本字符串按其最相似的标签分类)
用户接入层
嵌入包含两个方法,一个用于嵌入文档,接受多个文本作为输入;一个用于嵌入查询,接受单个文本。数据接入层的嵌入属于第一种,而用户接入层的嵌入旨在将输入的问题嵌入到模型中作为查询。
向量相似度匹配
例如:”机器学习”表示为 [1,2,3]
“深度学习”表示为[2,3,3]
“英雄联盟”表示为[9,1,3]
使用余弦相似度(余弦相似度是一种用于衡量向量之间相似度的指标,可以用于文本嵌入之间的相似度)在计算机中来判断文本之间的距离。
“机器学习”与“深度学习”的距离:
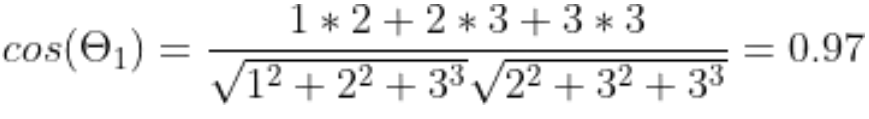
“机器学习”与“英雄联盟“的距离”:
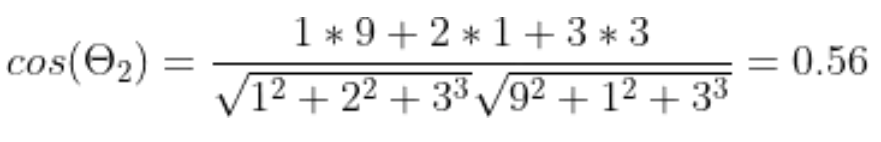
“机器学习”与“深度学习”两个文本之间的余弦相似度更高,表示它们在语义上更相似。
LLM终端输入构建
上述步骤通过将用户输入转为向量与上传文件的向量进行比较,得到文本库中较相似的文本块。但是为了更好匹配用户需求,使得模型回答的内容更为具体、更具条理、更高质量,就需要在LLM输入端进行Prompt工程。
**Prompt:**下游任务设计出来的一种输入形式或模板,能够帮助LLM“回忆”起自己在预训练时“学习”到的东西的方式。NLP新宠——浅谈Prompt的前世今生 - 知乎 (zhihu.com)
对于输入的文本x,有函数f_prompt(x),将x转化为prompt的形式x’。该函数通常会进行两步操作:
一是使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入x的位置[X]和用于生成答案文本z的位置[Z]。二是把输入x填到[X]的位置。
在文本情感分类的任务中,假设输入是 X = “ I love this movie.” 。使用的模板是 “ [X] Overall, it was a [Z] movie.”
那么得到的x′就应该是 “I love this movie. Overall it was a [Z] movie.”
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。[X]和[Z]的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
下一步会进行答案搜索,顾名思义就是LM寻找填在[X]处可以使得分数最高的文本 z^ 。最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出z^。例如,在文本情感分类任务中,”excellent”, “great”, “wonderful” 等词都对应一个种类 “++”,这时需要将词语映射到标签再输出。
Step 1:Prompt Templates(提示模板,根据用户提示动态格式化输入)
LangChain:Prompt Templates介绍及应用_prompttemplate-CSDN博客
在自然语言生成任务中,生成高质量的文本是非常困难的,尤其是当需要针对不同的主题、情境、问题或任务进行文本生成时,需要花费大量的时间和精力去设计、调试和优化模型,而这种方式并不是高效的解决方案。因此,Prompt Templates技术应运而生,可以大大降低模型设计、调试和优化的成本。
Prompt Templates是一种可复制的生成Prompt的方式,它包含一个文本字符串,可以接受来自终端用户的一组参数并生成Prompt。Prompt Templates可以包含指令、少量示例和一个向语言模型提出的问题。Prompt Templates可以帮助我们指导语言模型生成更高质量的文本,从而更好地完成我们的任务。
比如:帮我翻译以下文字{text},采用{style}风格。
在该模板内,prompt Templates包含两个变量,{text}{style},因此用户在输入时可以指定这两个变量,比如帮我把。。。翻译成美式英语。
因此Prompt Templates一般包含:
- 对语言模型的指令;
- 一组few-shot examples,以帮助语言模型生成更好的响应;
- 对语言模型的问题。
其中few-shot examples是一组可用于帮助语言模型生成更好响应的示例。要生成具有few-shot examples的prompt,可以使用FewShotPromptTemplate。该类接受一个PromptTemplate和一组few-shot examples。然后,它使用这些few-shot examples格式化prompt模板。
Step 2:output parser(输出解析器,规范输出)
LLM模型生成的都是文本,但是我们通常期望能够获取到一些结构化的输出,以便后续进一步处理。而Output Parsers的主要作用是将LLM的文本解析为结构化的数据。
在LangChain的Output Parsers中,必须要实现两个方法:
getFormatInstructions(): str该方法返回一个包含语言模型输出格式说明的字符串,简单来说就是告诉LLM模型应该以何种格式返回数据。parse(raw: string): any该方法是将一个原始字符串raw解析为一个特定结构的数据
Step 3:Example Selectors(示例选择器)
为了让LLM的输出符合自己期望的文本,可以通过Few-shot(少样本)的方式,即给出一些示例,让LLM生成与示例相似的文本。Few-shot这种方式可以一定程度上避免LLM输出质量波动过大的问题,但是同样也会引入一些其他问题例如,过于遵循示例的风格,导致有时候会有种强行拼凑的感觉。Example Selector就是负责帮助你构建一个Few-shot的Prompt。ExampleSelector接受一个最大长度的参数,可以根据用户的输入长度,动态的选择示例的个数,以保证最终的Prompt不会超过LLM模型对于Prompt的长度限制。
Langchain组件
一文详解最热的 LLM 应用框架 LangChain - 知乎 (zhihu.com)
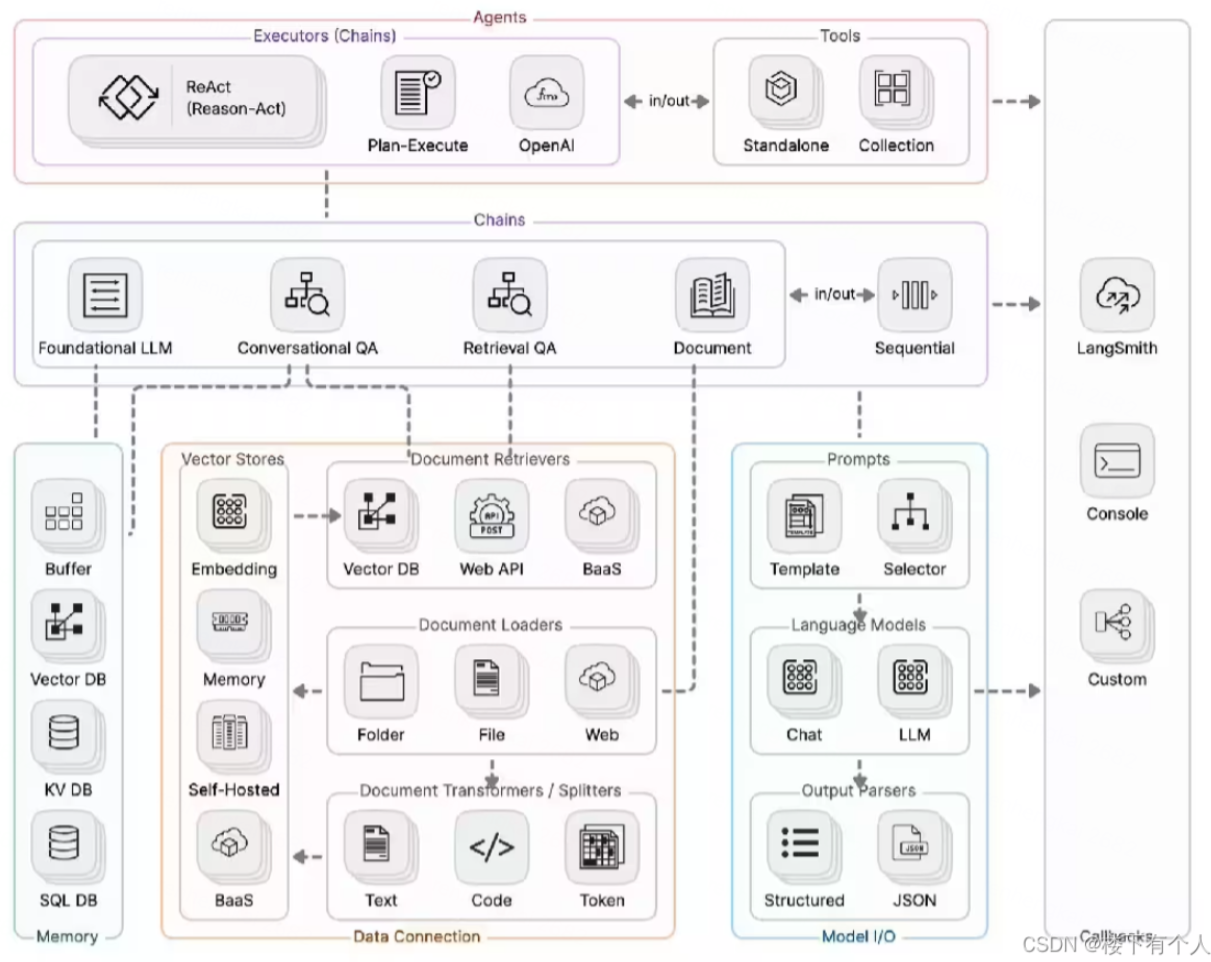
Langchain主要组件
- Model I/O:管理大语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers)
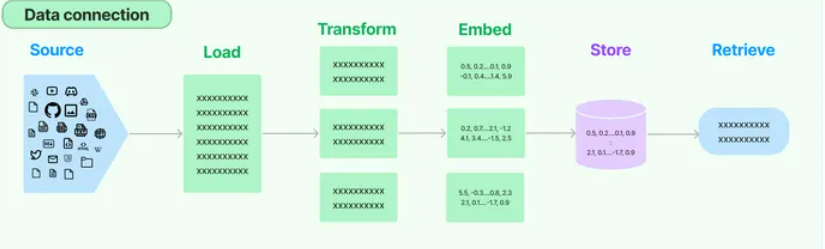
- Data connection:管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers)
- Memory:用于存储和获取 对话历史记录 的功能模块
- Chains:用于串联 Memory ↔️ Model I/O ↔️ Data Connection,以实现 串行化 的连续对话、推测流程
- Agents:基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合
- Callbacks:提供了一个回调系统,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流
Langchain核心模块架构图
Langchain搭建个人专属知识库
使用方法
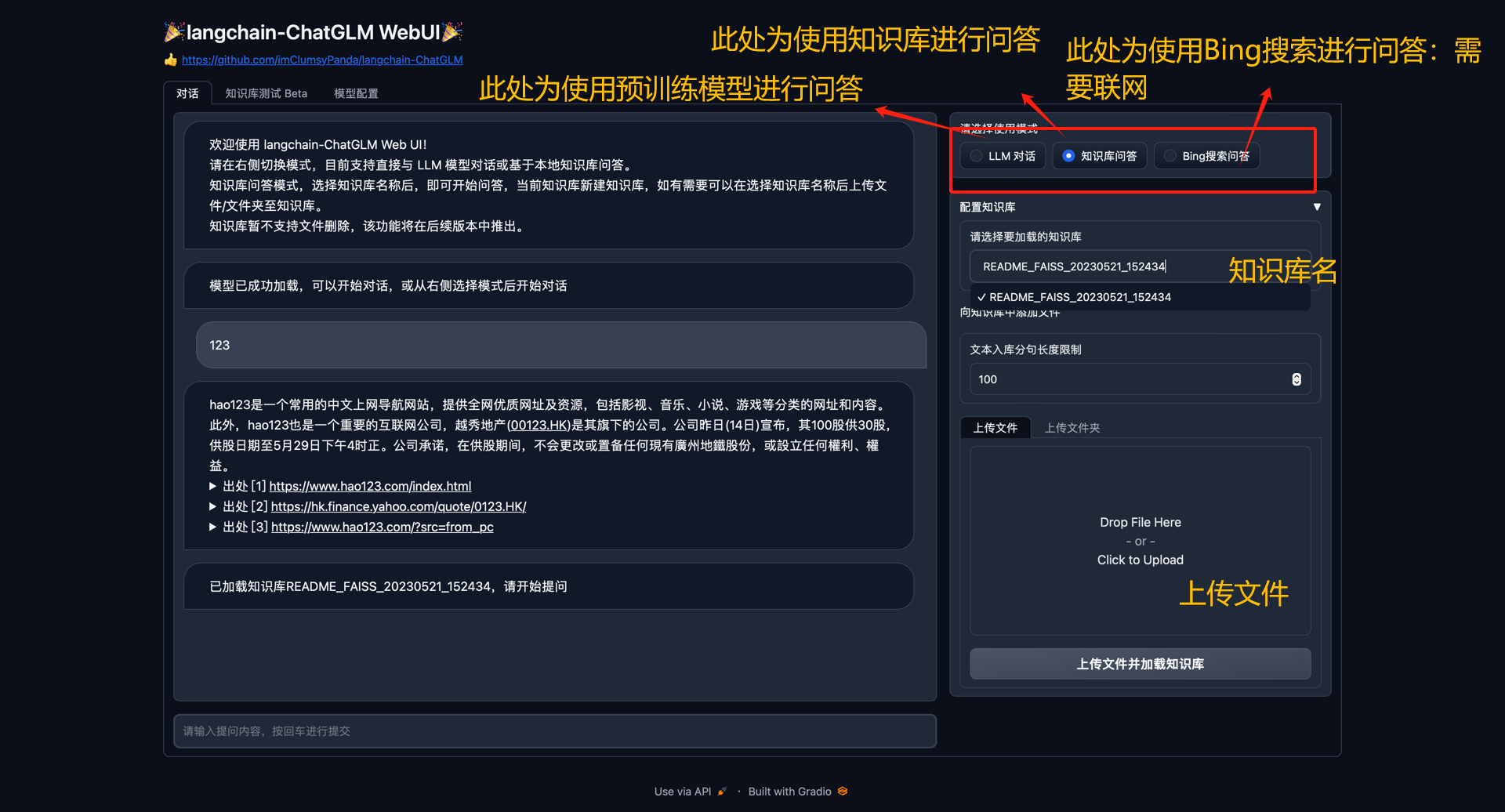
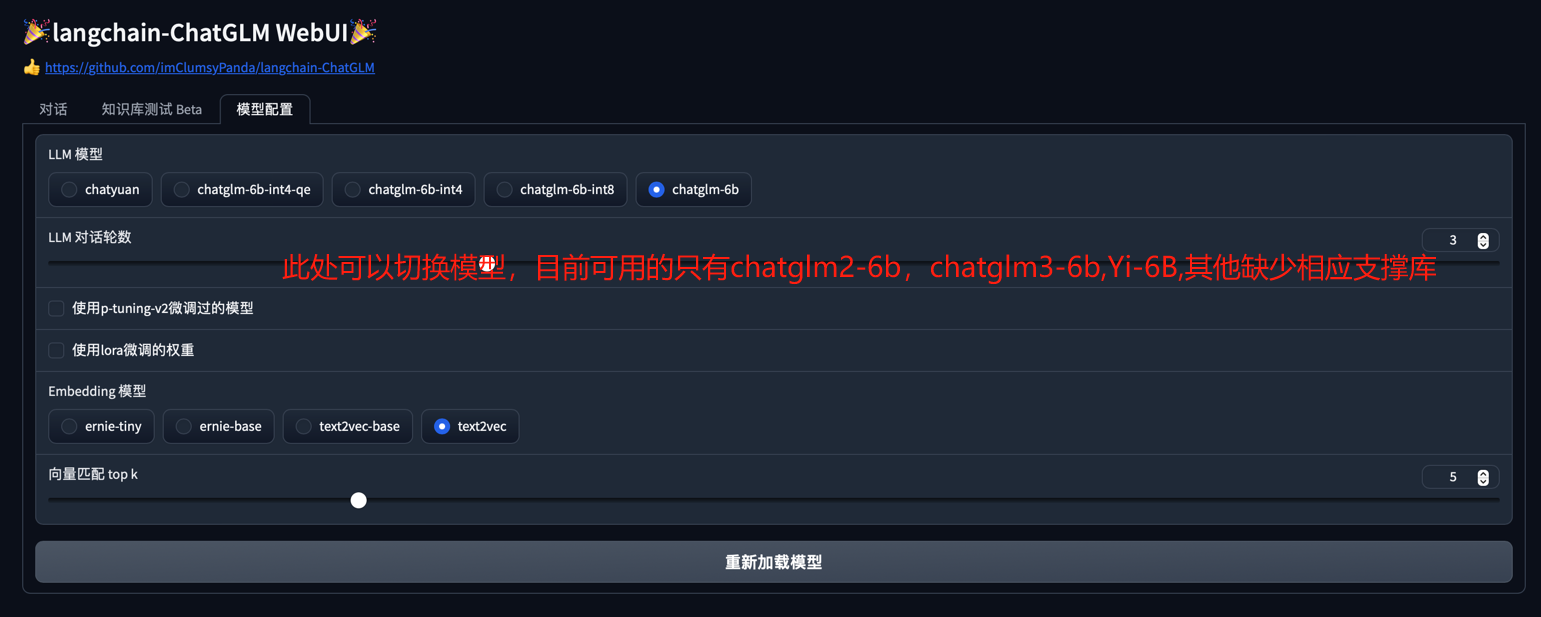
Web UI 可以实现如下功能:
- 运行前自动读取
configs/model_config.py中LLM及Embedding模型枚举及默认模型设置运行模型,如需重新加载模型,可在模型配置Tab 重新选择后点击重新加载模型进行模型加载; - 可手动调节保留对话历史长度、匹配知识库文段数量,可根据显存大小自行调节;
对话Tab 具备模式选择功能,可选择LLM对话与知识库问答模式进行对话,支持流式对话;- 添加
配置知识库功能,支持选择已有知识库或新建知识库,并可向知识库中新增上传文件/文件夹,使用文件上传组件选择好文件后点击上传文件并加载知识库,会将所选上传文档数据加载至知识库中,并基于更新后知识库进行问答; - 新增
知识库测试 BetaTab,可用于测试不同文本切分方法与检索相关度阈值设置,暂不支持将测试参数作为对话Tab 设置参数。 - 后续版本中将会增加对知识库的修改或删除,及知识库中已导入文件的查看
Note: Langchain的知识库检索本质就是AI理解所给的文本内容,然后根据要求进行回答。所以如果问到与知识库无关的内容会出现答非所问的情况。
因此,如果像完美的适应下游任务,需要进行微调或者prompt。
微调是指在已有的预训练语言模型基础上,通过少量的数据来对模型进行进一步的训练,使得模型能够更好地适应新的任务或领域。微调的目的是利用已有的语言模型,尽量减少训练新模型的时间和资源消耗。因此,微调是一种快速迁移学习的方法。
而prompt是指为了训练特定类型的语言模型而设计的一系列文本或代码提示。prompt可以看作是一种能够帮助语言模型更好地理解特定任务或领域的“指令”。prompt通常包括一个问题、任务描述或预定义的文本片段,用于指导模型生成合适的文本结果。融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“。在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model,在文本情感分类任务中,对于 “I love this movie.” 这句输入,可以在后面加上prompt “The movie is ___” 这样的形式,然后让PLM用表示情感的答案填空如 “great”、“fantastic” 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。(原文链接:https://blog.csdn.net/qq_44324007/article/details/129687988)