有关于大模型部署的一些补充.
大模型的界面显示
一种基于gradio库的方式:
1 | import numpy as np |
效果图:
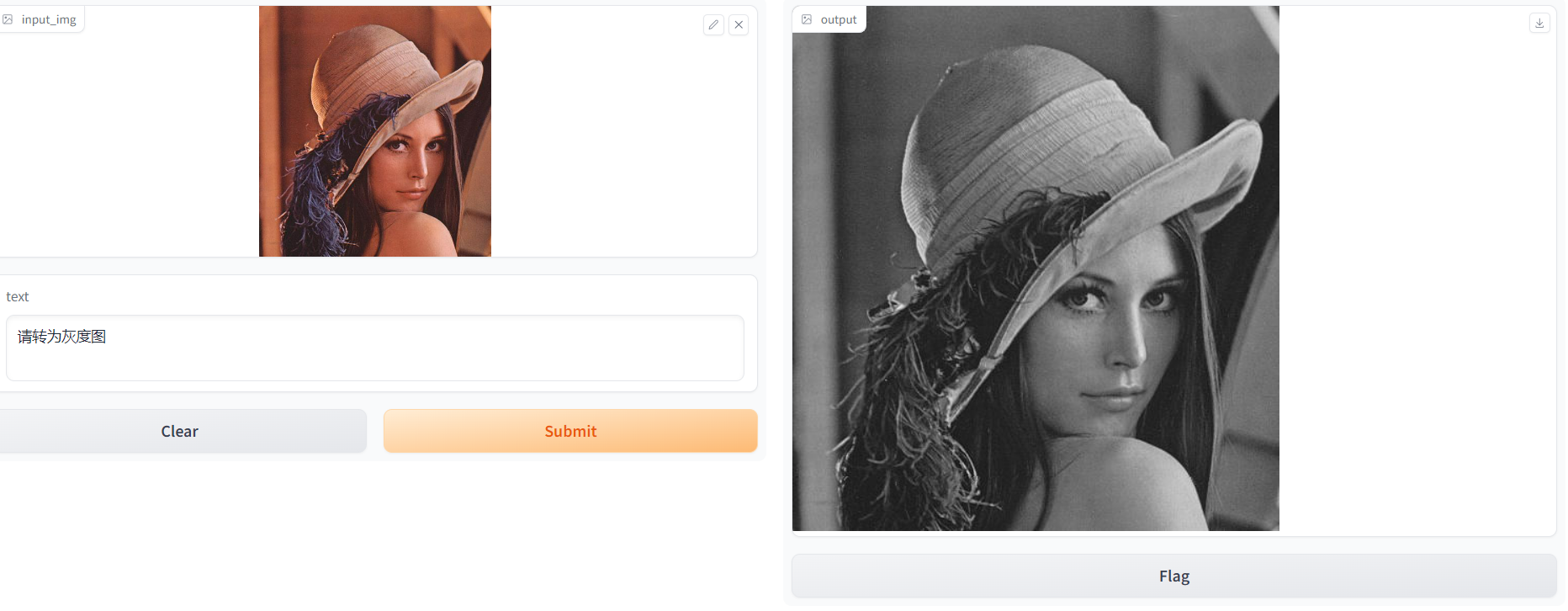
微调
为什么微调
通常,要对大模型进行微调,有以下一些原因:
- 因为大模型的参数量非常大,训练成本非常高,每家公司都去从头训练一个自己的大模型,这个事情的性价比非常低;
- Prompt Engineering的方式是一种相对来说容易上手的使用大模型的方式,但是它的缺点也非常明显。因为通常大模型的实现原理,都会对输入序列的长度有限制,Prompt Engineering 的方式会把Prompt搞得很长。越长的Prompt,大模型的推理成本越高,因为推理成本是跟Prompt长度的平方正向相关的。另外,Prompt太长会因超过限制而被截断,进而导致大模型的输出质量打折口,这也是一个非常严重的问题。对于个人使用者而言,如果是解决自己日常生活、工作中的一些问题,直接用Prompt Engineering的方式,通常问题不大。但对于对外提供服务的企业来说,要想在自己的服务中接入大模型的能力,推理成本是不得不要考虑的一个因素,微调相对来说就是一个更优的方案。
- Prompt Engineering的效果达不到要求,企业又有比较好的自有数据,能够通过自有数据,更好的提升大模型在特定领域的能力。这时候微调就非常适用。
- 要在个性化的服务中使用大模型的能力,这时候针对每个用户的数据,训练一个轻量级的微调模型,就是一个不错的方案。
- 数据安全的问题。如果数据是不能传递给第三方大模型服务的,那么搭建自己的大模型就非常必要。通常这些开源的大模型都是需要用自有数据进行微调,才能够满足业务的需求,这时候也需要对大模型进行微调。
如何微调
1)一条是对全量的参数,进行全量的训练,这条路径叫全量微调FFT(Full Fine Tuning)。
FFT的原理,就是用特定的数据,对大模型进行训练,将W变成W,W相比W ,最大的优点就是上述特定数据领域的表现会好很多。
但FFT也会带来一些问题,影响比较大的问题,主要有以下两个:
- 一个是训练的成本会比较高,因为微调的参数量跟预训练的是一样的多的;
- 一个是叫灾难性遗忘(Catastrophic Forgetting),用特定训练数据去微调可能会把这个领域的表现变好,但也可能会把原来表现好的别的领域的能力变差。
2)一条是只对部分的参数进行训练,这条路径叫PEFT(Parameter-Efficient Fine Tuning)。
主要针对解决FFT的两个问题,主要方法在前面已经介绍。
微调前后变化
微调一般分为两种:
- 一种是改变大模型原有任务,即原来是文本翻译、图像生成等回归任务,借助原本模型对文本的理解、语言的结构理解,通过微调改成分类任务。比如Bert模型原本是自然语言理解的任务,可以微调改为文本分类、情感分析的分类任务。这类任务对于他前后的效果无法比较;
- 另一种就是还是原来的任务,原本是Question and answer的任务,通过微调,添加当前领域特有的数据集使得它更适用于当前的任务。
以下为两个案例对应两种类型的微调:
案例2:
该案列为ChatGLM2微调保姆级教程~ - 知乎 (zhihu.com)中进行的一个微调,主要任务是基于ChatGLM2-6b,使用外卖评论数据集来实施微调,让ChatGLM2-6b来对一段外卖评论区分是好评还是差评。
数据集格式是:
1 | 味道真不错 -> 好评 |
拿外卖数据集测试一下未经微调,纯粹的 6-shot prompt 的准确率:

改为分类任务,微调后跌准确率:0.903
用6000条数据,训练了一个小时左右,准确率到了90.3%,比未经微调的prompt方案的87.8%相比涨了两个多点~
案例1:
Jina AI Finetuner,使用如下3种数据集探索在VIT模型中的提升:

微调结果如下:
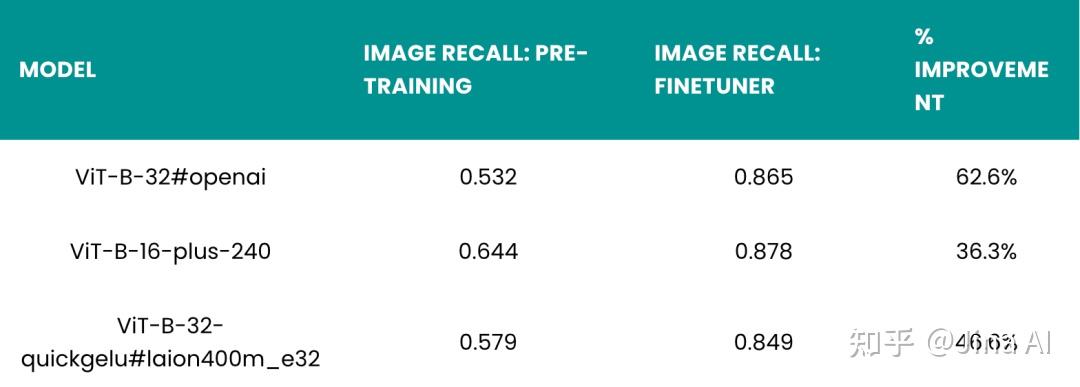
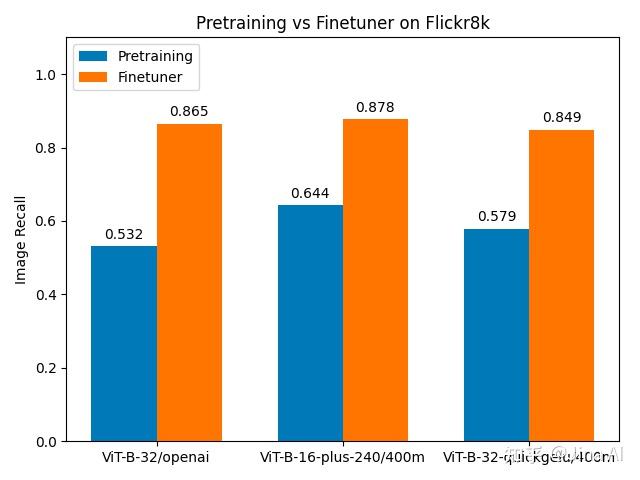
Finetuner 给那些使用 CLIP 模型预训练得到的图像召回率最差的数据集带来了最大的改进。对于 Flickr8k 数据集,微调前的召回率在 0.5 到 0.65 之间,微调后的召回率可以达到 0.85 或者更高,这代表通过微调,召回率增加了 36% 到 63%。
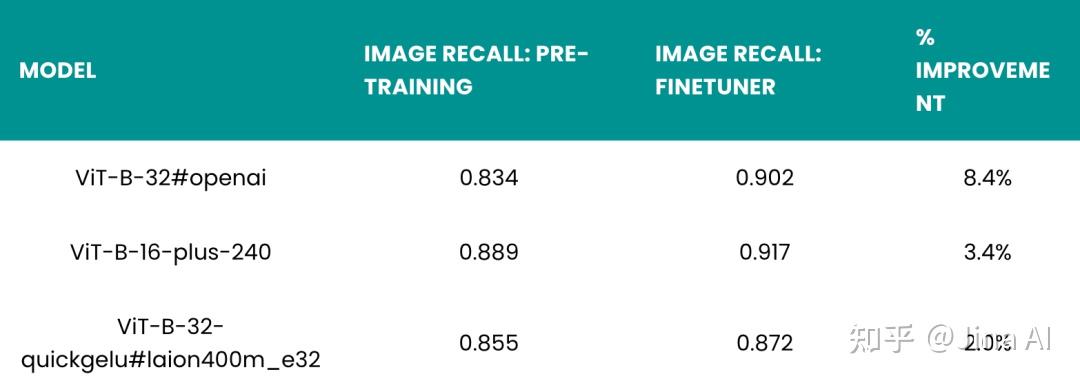
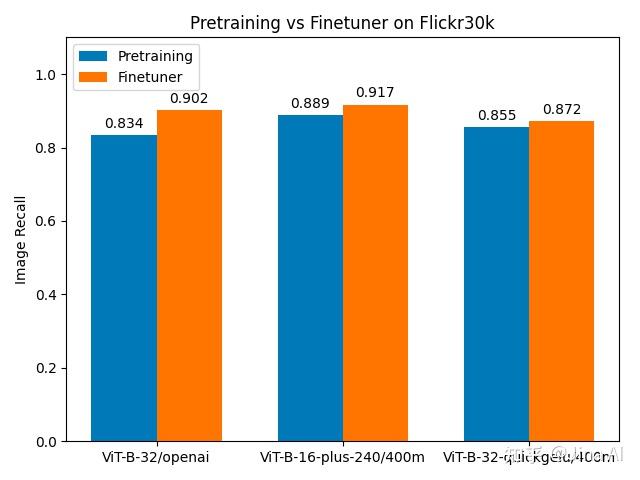
对于 Flickr30k 数据集,相比于仅使用预训练的模型,使用微调后模型的召回率更高,但提升不明显:三个模型的召回率提升都在 10% 以下。这说明,当预训练模型的性能已经很好的情况下,微调模型的提升空间并不大。尽管 Finetuner 在提升 Flickr30k 数据集的召回率方面效果并不明显,但它仍然可以显著提高所有模型的性能。
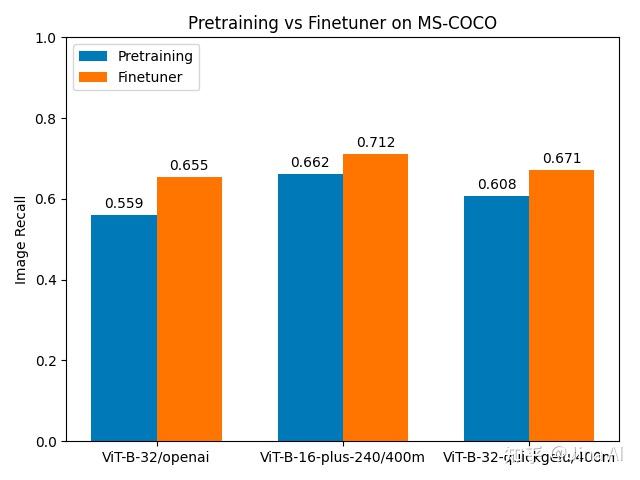
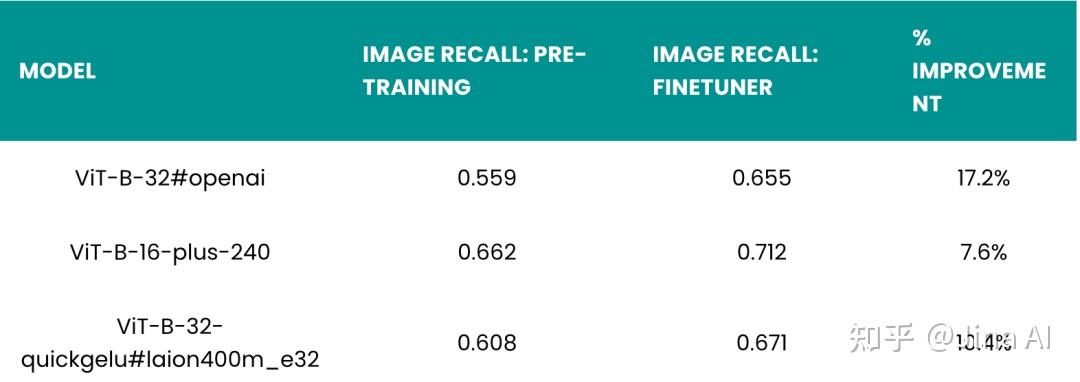
对于 MS-COCO 数据集,虽然预训练模型的召回率略高于 Flickr8k 数据集,但微调后的提升比 Flickr8k 数据集小得多:从 7% 提升到 17%,具体取决于模型。由于 MS-COCO 是一个更大、更多样化的数据集,所以可以预知给定相同的训练超参数时,改进会更小,但这依然比 Flickr30k 数据集的提升大得多。
微调需要多少数据
关于微调需要多大数据集一般是就任务复杂度而言,目前并没有明确的规定。但关于数据集构成这里给出以下调研结果:
调研1:
《LIMA:Less Is More for Alignment》、《MAYBE ONLY 0.5% DATA IS NEEDED》两篇文章,在说明小数据量上,提出了更新颖的结论。
《LIMa:Less Is More for Alignment》一文的消融实验显示,当扩大数据量而不同时扩大提示多样性时,收益会大大减少,而在优化数据质量时,收益会大大增加。
《MAYBE ONLY 0.5% DATA IS NEEDED》一文的实验表明,特定任务的模型可能从固定的任务类型中获益,以获得更高的性能; 指令格式的多样性可能对特定任务模型的性能影响很小;即使是少量的数据(1.9M tokens)也能为特定任务模型的指令调整带来可喜的结果。
多样性,高质量这两个数据上的问题一直被认定是决定模型性能的天花板。
调研2(案例可参考调研3的内容):
和ChatGLM的作者的QA。
Q:如果要基于chatGLM微调出一个具备垂直领域知识的模型,这个数据集大致需要多大的规模呢?几万条问答对吗?
A:直接加一小部分做监督的话,可能会让小模型原有的通用能力丧失。所以最好的策略,应该是不要太去动这个模型,除非你有很多、很好的微调数据,否则直接微调,在你只有几万条以下的数据的情况下,你想要靠微调取得一个很理想的效果是有点困难的。更好的方式应该是,针对一个具体的问题,给他找一些参考资料,把它拼接到你给模型的prompt中,通过模型本身的能力来解决。
调研3https://www.zhihu.com/question/596950521/answer/3109759716:
summary:
(1) 只需要1条样本,很少的训练时间,就可以通过微调给LLM注入知识。
(2) LLM是一种类似Key-Value形式的知识数据库,支持增删改查。通过微调可以增删修改知识,通过条件生成可以查询提取知识。
(3) LoRA微调是一种高效的融入学习算法。类似人类把新知识融入现有知识体系的学习过程。学习时无需新知识特别多的样本,学习后原有的庞大知识和能力可以基本不受影响。
before:
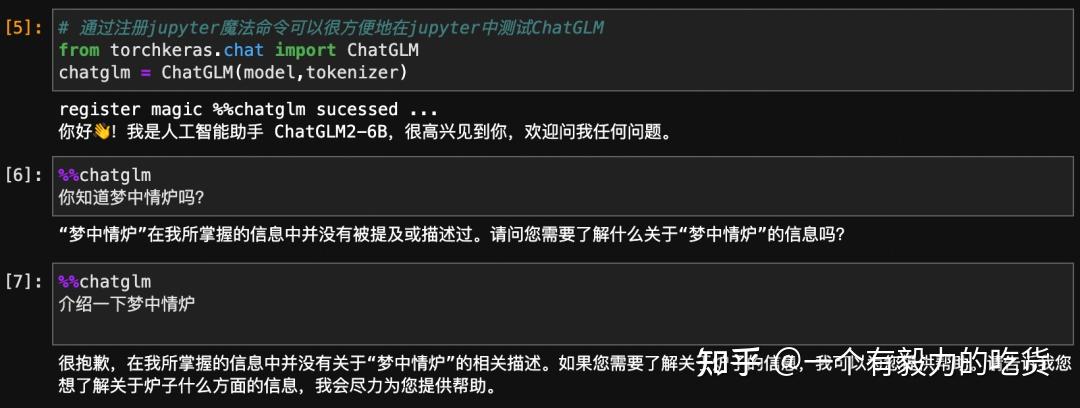
after:
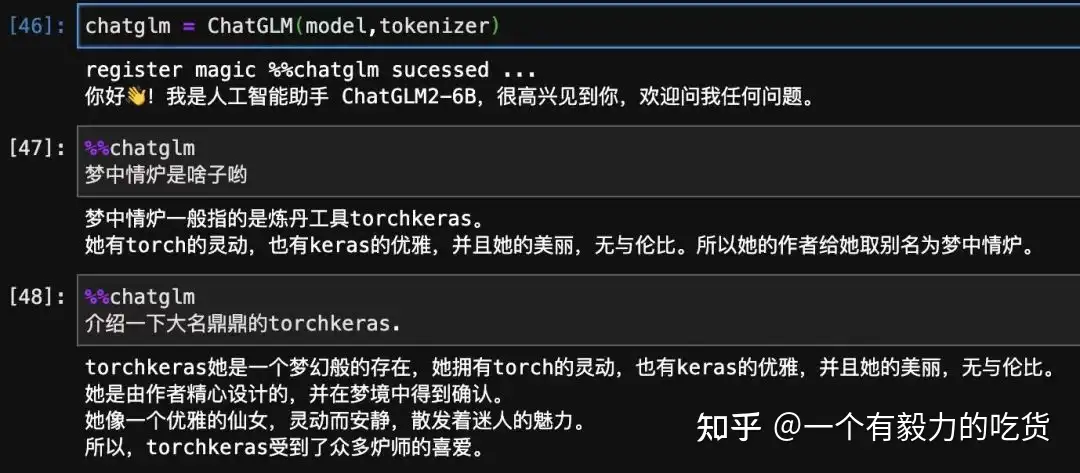
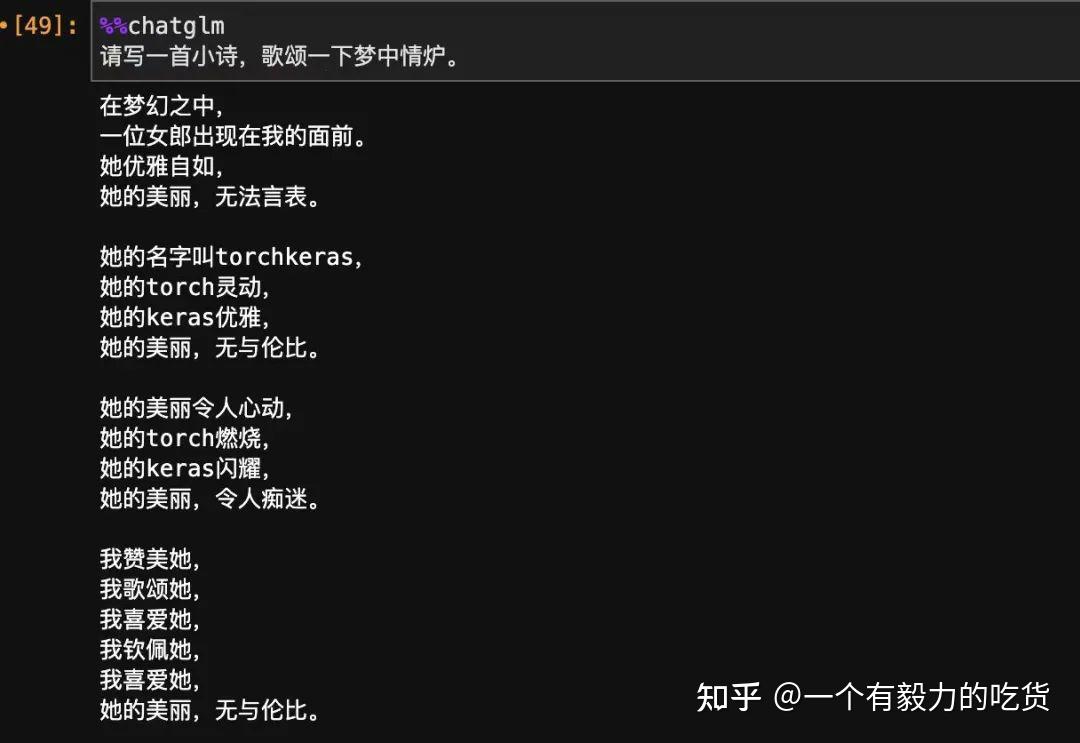
方法:
1 | #定义一条知识样本~ |
微调需要的算力
微调需要多少算力,取决于两点,一是模型原来有多大,二是采用何种微调方法。
如以下案例:
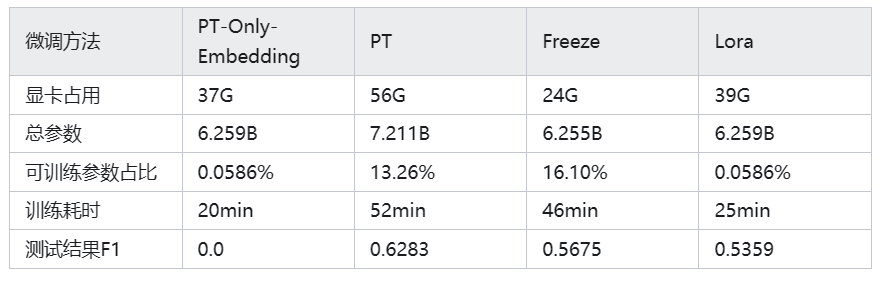
- 效果为PT>Freeze>Lora>PT-Only-Embedding;
- 速度为PT-Only-Embedding>Lora>Freeze>PT;
- PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务;
- PT方法占用显存更大,因为也增加了很多而外参数;
- 测试耗时,采用float16进行模型推理,由于其他方法均增加了额外参数,因此其他方法的推理耗时会比Freeze方法要高。当然由于是生成模型,所以生成的长度也会影响耗时;
- 模型在指定任务上微调之后,并没有丧失原有能力,例如生成“帮我写个快排算法”,依然可以生成-快排代码;
- 由于大模型微调都采用大量instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失;