该篇是我第二段实习经历的第一篇工作,主要是探索大模型,大多是缝合的各大博主的一些独到见解与总结。
主要内容为:大模型的定义、大语言模型的使用场景、大语言模型的介绍(分类、演化过程及趋势、各个类别的特定及总结)、什么情况下选择使用大模型、大模型的参数量、大模型的使用指南(整个训练过程、下游任务的微调过程及案例实操),最后过渡到视觉大模型。介绍了视觉大模型的基本知识、分类,以及按照分类介绍了目前一些主流大模型的特点与应用。
大模型
大模型,泛指参数很多的机器学习模型(具体请参考:大模型多大算大),根据场景不同,大部分大模型公司把大模型分为大语言模型、计算机视觉(包含图像和视频)、音频、多模态大模型四大类。
要有效和高效地利用这些模型,需要对它们的功能和局限性以及数据和任务的特征有实际的了解。
针对特定任务选择合适模型:模型大小、计算需求和特定领域预训练模型的可用性等因素。
[^LLMs]: Large Language Models
大语言模型的使用场景
- 自然语言理解(Natural language understanding):在面对分布外数据或训练数据很少时,利用 LLMs 卓越的泛化能力。
- 生成(Generation):利用LLMs为各种应用程序创建连贯的、上下文相关的、高质量的文本和代码。
- 知识密集型的任务(Knowledge-intensive tasks):利用LLMs存储的广泛知识来完成需要特定领域专业知识或一般世界知识的任务。
- 推理能力(Reasoning ability):理解和利用LLMs的推理能力,以提高在各种情况下的决策和解决问题。
- 真实世界场景(Real world scenarios):利用LLMs在现实场景中的优势,能够处理嘈杂的输入,处理非正式的任务,并在对齐后遵循人工指令。
(1)LLM 在面临分布外数据的下游任务(例如对抗性示例和领域转移)中比微调模型具有更好的泛化能力。
(2)当使用有限的注释数据时,LLM 优于微调模型,并且当有大量注释数据可用时,两者都是合理的选择,具体取决于特定的任务要求。
大模型介绍
大模型有哪些
1)分类
non-causal attention language models/encoder-only
half-causal attention language models /encoder-decoder
causal attention language models/decoder-only
2) 详细演化过程
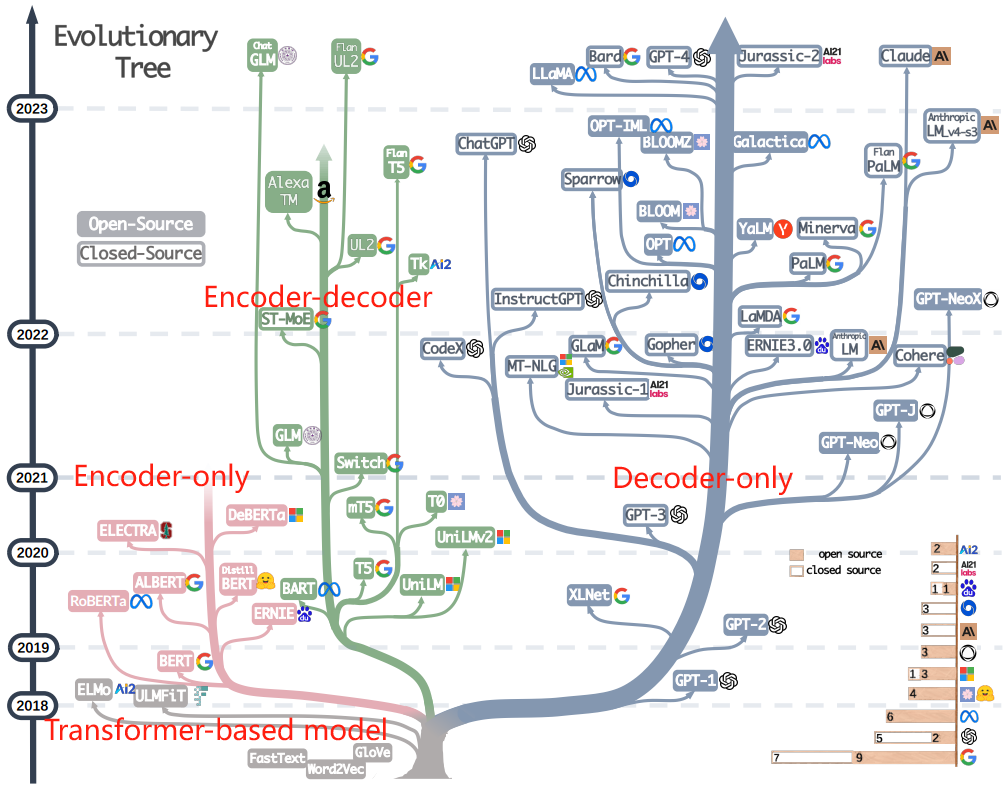
3) 演化趋势
- Decoder-only 模型逐渐主导了 LLM 的发展:在 LLMs发展的早期阶段,decoder-only 模型不如 encoder-only 和 encoder-decoder 模型流行。然而,在 2021 年之后,随着改变游戏规则的 LLMs——GPT-3 的推出,仅解码器模型经历了显着的繁荣。与此同时,在 BERT 带来的初期爆发式增长之后,encoder-only 模型逐渐开始淡出市场。
- OpenAI 始终保持其在 LLMs 领域的领先地位,无论是现在还是未来。其他公司和机构在开发可与 GPT-3 和当前的 GPT-4 相媲美的模型方面正在努力追赶 OpenAI。这一领先地位可能归因于 OpenAI 对其技术道路的坚定承诺,即使它最初并未得到广泛认可。
- Meta 对开源 LLMs 做出了重大贡献,并促进了 LLMs 的研究。在考虑对开源社区的贡献时,尤其是那些与 LLM 相关的贡献时,Meta 脱颖而出,成为最慷慨的商业公司之一,因为 Meta 开发的所有 LLM 都是开源的。
- LLMs表现出封闭采购的趋势。在 LLMs发展的早期阶段(2020 年之前),大多数模型都是开源的。然而,随着 GPT-3 的推出,公司越来越多地选择闭源他们的模型,例如 PaLM、LaMDA 和 GPT-4。因此,学术研究人员就 LLMs 培训进行实验变得更加困难。因此,基于 API 的研究可能成为学术界的主要方法。
- 编码器-解码器模型仍然很有前途,因为这种类型的架构仍在积极探索中,而且其中大部分是开源的。谷歌对开源编码器-解码器架构做出了重大贡献。然而,decoder-only 模型的灵活性和通用性似乎让谷歌在这个方向上的坚持变得不那么有希望了。
4)BERT-style 语言模型:Encoder only/Non-causal attention models
由于自然语言数据很容易获得,并且已经提出了无监督训练范式来更好地利用超大数据集,这激发了自然语言的无监督学习。非因果模型是最早引发讨论的预训练语言模型之一。它们是仅限编码的模型,采用了在考虑周围上下文的情况下预测句子中隐藏词的方法。这种训练范式被称为掩码语言建模。顾名思义,对于这样的模型,所有的输入标记在注意机制中是相互可见的,而不遵循语言的伤亡。非因果模型的著名例子包括BERT和RoBERTa。非因果模型在自然语言理解领域表现出良好的性能。
5)GPT语言模型:Decoder only/Causal attention models
尽管语言模型在体系结构中通常与任务无关,但这些方法需要对特定下游任务的数据集进行微调。研究人员发现,扩大语言模型可以显着提高少样本甚至零样本的性能 。为获得更好的 few-shot 和 zero-show 性能,最成功的模型是自回归语言模型,它是通过在给定前面的单词的情况下生成序列中的下一个单词来训练的。这些模型已广泛用于下游任务,例如文本生成和问答。自回归语言模型的示例包括 GPT-3 、OPT 、PaLM 和 BLOOM 。游戏规则改变者 GPT-3 首次通过提示和上下文学习展示了合理的少样本/零样本性能,从而显示了自回归语言模型的优越性。还有 CodeX 等模型 , 针对特定任务进行了优化,例如金融领域的代码生成、BloombergGPT 。最近的突破是 ChatGPT,它专门针对对话任务改进了 GPT-3,从而为各种现实世界的应用程序带来更具交互性、连贯性和上下文感知的对话。
6)Decoder-encoder/Half-causal attention models
半因果模型包括编码器-解码器模型和具有特殊预训练目标的解码器模型 prefixLM。半因果模型表现出介于其他两种模型之间的特征。对于这样的模型中,输入文本的注意机制可分为两部分。初始部分与非因果注意模型,不遵循符号的因果顺序。对于编码器-解码器模型,它是对于具有prefixLM目标的模型,它是前缀部分。但后一部分表现得像因果关系注意模型,每个标记只包含来自它之前标记的信息。这些模型的最初动机之一是为了提高非因果注意模型的生成能力。T5、UniLMv2、BART等许多流行的模型都属于这一类。
7)总结
LLM的3种类型,encoder-only、decoder-only、encoder-decoder。
encoder:理解上下文之间的关系,将输入序列编码成一个固定长度的向量;
decoder:将固定长度的向量解码成一个可变长度的输出序列(Decoder主要是是为了预测下一个输出的内容/token是什么,并把之前输出的内容/token作为上下文学习)。
上述三种都属于Seq2Seq,sequence to sequence。
Encoder-only:只有编码器encoder,实际上LLMs是能decoder一些文本和token的,也算是decoder。不过由于encoder-only类型的LLM不像decoder-only和encoder-decoder那些有自回归autoregressive,encoder-only集中于理解输入的内容,并做针对特定任务的输出自回归指输出的内容是根据已生成的token做上下文理解后一个token一个token输出的。总的来说,encoder-only类型的更擅长做分类;encoder-decoder类型的擅长输出强烈依赖输入的,比如翻译和文本总结,而其他类型的就用decoder-only,如各种Q&A。虽然encoder-only没有decoder-only类型的流行,但也经常用于模型预训练。Encoder-only架构的LLMs更擅长对文本内容进行分析、分类,包括情感分析,命名实体识别。
Decoder-only:decoder-only模型在分析分类上也和encoder only的LLM一样有效。Decoder-only的decoder层跟encoder相似,不过在位置position上用到了mask。
在 Transformer 模型的解码器中,自注意力机制允许每个位置的输出都依赖于输入序列中所有位置的信息。然而,当生成输出序列(例如在文本翻译任务中生成目标语言的文本)时,我们希望位置 i 的输出只依赖于位置 i 之前的已知输出,而不依赖于位置 i 之后的输出。为了实现这一点,使用了一种“掩码”技术,阻止模型关注位置 i 之后的位置。这意味着,在进行解码器的自注意力运算时,位置 i 的注意力分布(即注意力权重)只会在位置 i 及其之前的位置上,不会在位置 i 之后的位置上。这样,就可以确保位置 i 的输出只依赖于位置 i 之前的已知输出。输出的内容也是一个token。
Encoder-decoder: 这种架构的LLM通常充分利用了上面2种类型的优势,采用新的技术和架构调整来优化表现。这种主要用于NLP,即理解输入的内容NLU,又能处理并生成内容NLG,尤其擅长处理输入和输出序列之间存在复杂映射关系的任务,以及捕捉两个序列中元素之间关系至关重要的任务。
大模型的数据以及什么时候使用大模型
1)预训练数据
预训练数据在大型语言模型的开发中起着举足轻重的作用。作为 LLM 卓越能力的基础 ,预训练数据的质量、数量和多样性显着影响 LLM 的性能 。常用的预训练数据由无数的文本来源组成,包括书籍、文章和网站。这些数据经过精心挑选,以确保全面反映人类知识、语言差异和文化观点。(来源)
预训练数据的重要性在于它能够为语言模型提供对单词知识、语法、句法和语义的丰富理解,以及识别上下文和生成连贯响应的能力。(作用)
预训练数据的多样性在塑造模型性能方面也起着至关重要的作用,LLM 的选择在很大程度上取决于预训练数据的组成部分。例如,PaLM 和 BLOOM 在多语言任务和机器翻译方面表现出色,具有丰富的多语言预训练数据。此外,通过结合大量社交媒体对话和图书语料库,PaLM 在问答任务中的表现得到了提升。同样,GPT-3.5 (code-davinci-002) 的代码执行和代码完成能力通过将代码数据集成到其预训练数据集中得到了增强。简而言之,在为下游任务选择 LLM 时,建议选择在类似数据领域预训练的模型。(不同的大模型适合的场景不同,选择的预训练数据也要有针对)
2)微调数据
在为下游任务部署模型时,必须根据注释数据的可用性考虑三个主要场景:零样本,少量样本,丰富样本。
(1) Zero annotated data:在注释数据不可用的情况下,在零样本设置中使用 LLM 被证明是最合适的方法。 LLM 已被证明优于以前的零样本方法。此外,由于语言模型参数保持不变,因此没有参数更新过程可确保避免灾难性遗忘 。
(2)Few annotated data:在这种情况下,few-shot examples 直接合并到 LLMs 的输入提示中,称为上下文学习,这些示例可以有效地指导 LLMs 泛化到任务。单次和少次射击性能获得显着提升,甚至可以与 SOTA 微调开放域模型的性能相媲美。 LLM 的零/少镜头能力可以通过缩放进一步提高。或者,一些小样本学习方法被发明来增强微调模型,例如元学习或迁移学习。然而,由于微调模型的规模较小和过度拟合,与使用 LLM 相比,性能可能较差。
(3)Abundant annotated data:对于特定任务可用的大量注释数据,微调模型和 LLM 都可以考虑。在大多数情况下,微调模型可以很好地拟合数据。虽然,LLM 可以用来满足一些约束,例如隐私。在这种情况下,使用微调模型或 LLM 之间的选择是特定于任务的,并且还取决于许多因素,包括所需的性能、计算资源和部署约束。
简而言之:LLM更通用 w.r.t.数据可用性,而微调模型可以考虑具有丰富的注释数据。
数据少用预训练好的大模型,数据多,两者皆有自己的优点。
3) 测试数据/用户数据
在为下游任务部署 LLM 时,作者经常面临测试/用户数据与训练数据之间的分布差异所带来的挑战。这些差异可能包括领域转移、分布外的变化,甚至是对抗性的例子。这些挑战极大地阻碍了微调模式在实际应用中的有效性。它们适合特定的分布并且泛化到 OOD 数据的能力很差。然而,LLMs 在面对这种情况时表现得很好,因为它们没有明确的拟合过程。此外,最近的进展进一步增强了语言模型在这方面的能力。人类反馈强化学习 (RLHF) 方法显着增强了 LLM 的泛化能力。例如,InstructGPT 在执行各种任务方面表现出熟练的能力,并且偶尔会遵守不同语言的说明,即使此类说明很少见。同样,ChatGPT 在大多数对抗性和分布外 (OOD) 分类和翻译任务中表现出一致的优势 。它在理解对话相关文本方面的优势导致在 DDXPlus 数据集 上的表现令人印象深刻,DDXPlus 数据集是为 OOD 评估设计的医学诊断数据集。
上述内容均为文献:《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》
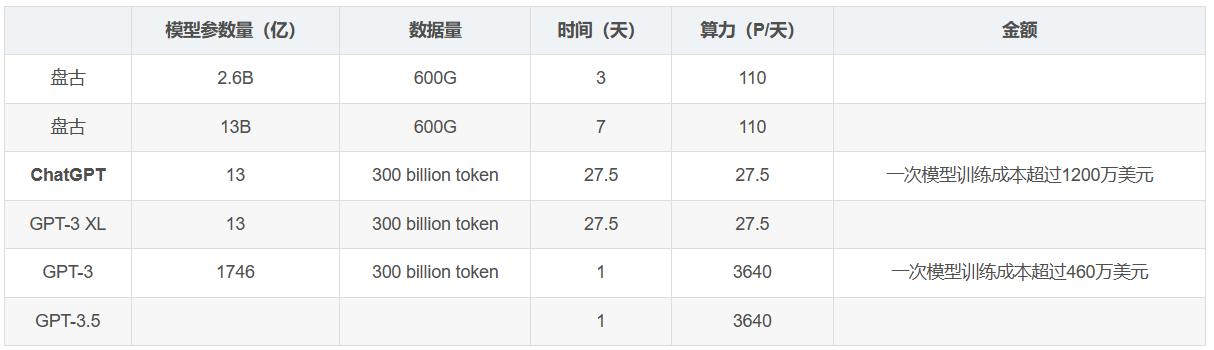
大模型的参数量
4 位量化 LLaMA 模型的 GPU 要求:

来源:https://gist.github.com/cedrickchee/255f121a991e75d271035d8a659ae44d
业界开源大模型关于算力、训练时长
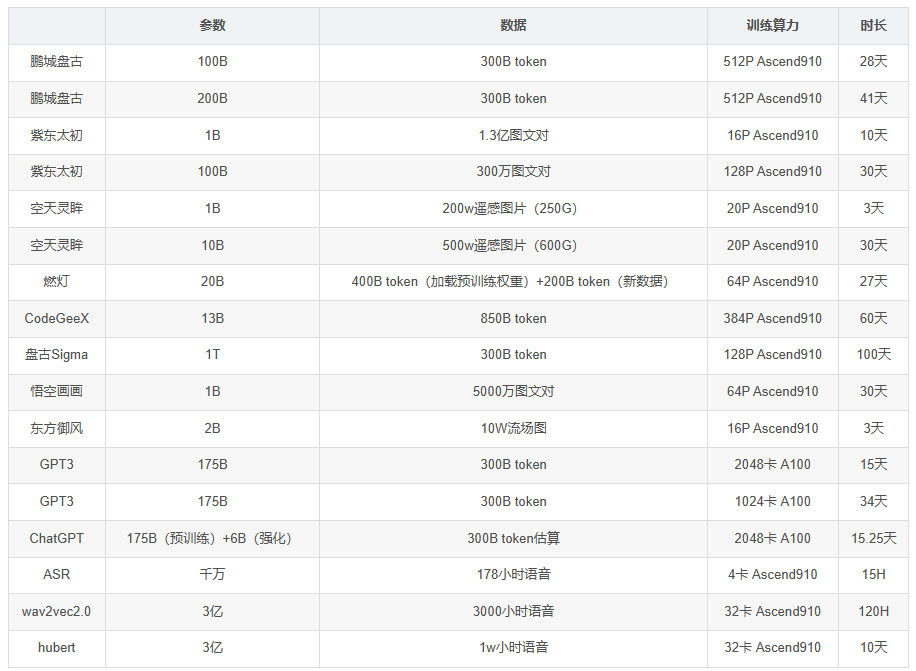
不同参数量下的算力要求
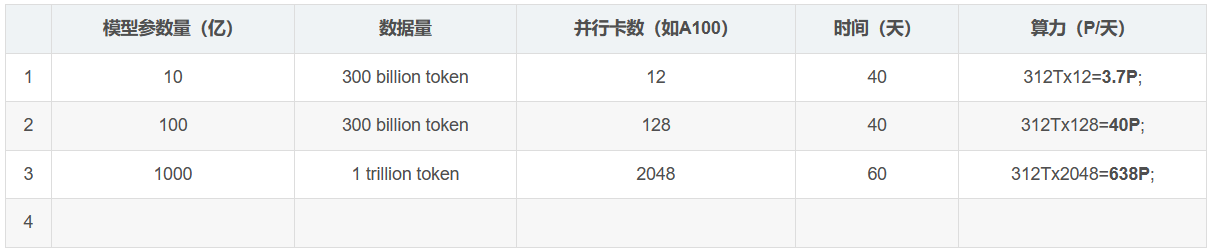
盘古一个token=0.75个单词,1token相当于1.5个汉字;
以中文为例:token和byte的关系
1GB=0.5G token=0.25B token;
典型的算力要求:
大模型使用指南
参考:【LLM】从零开始训练大模型 - 知乎 (zhihu.com)
1)LLaMA:大模型中的安卓(开源)。
2)大模型的三要素
1.算法: 模型结构,训练方法
2.数据: 数据和模型效果之间的关系,token分词方法
3.算力: 英伟达GPU,模型量化
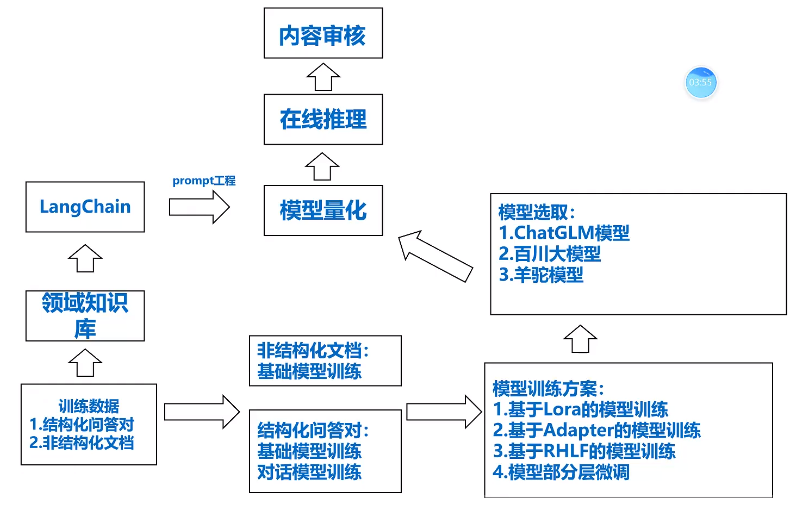
3)大模型的整个步骤(上游任务)
包括模型预训练(Pretrain)、指令微调(Instruction Tuning)、奖励模型(Reward Model)和强化学习(RLHF)等环节。
1.预训练阶段(Pretraining Stage)=>(数据、模型)
当前,不少工作选择在一个较强的基座模型上进行微调,且通常效果不错(如:[alpaca]、[vicuna] 等)。
这种成功的前提在于:预训练模型和下游任务的差距不大,预训练模型中通常已经包含微调任务中所需要的知识。
但在实际情况中,我们通常会遇到一些问题,使得我们无法直接使用一些开源 backbone:
1)语言不匹配:大多数开源基座对中文的支持都不太友好,例如:[Llama]、[mpt]、[falcon] 等,这些模型在英文上效果都很优秀,但在中文上却差强人意。
2) 专业知识不足:当我们需要一个专业领域的 LLM 时,预训练模型中的知识就尤为重要。由于大多数预训练模型都是在通用训练语料上进行学习,对于一些特殊领域(金融、法律等)中的概念和名词无法具备很好的理解。我们通常需要在训练语料中加入一些领域数据(如:[xuanyuan 2.0]),以帮助模型在指定领域内获得更好的效果。预训练任务主要分为以下几个步骤:
1.1 Tokenizer Training
在进行预训练之前,我们需要先选择一个预训练的模型基座。
一个较为普遍的问题是:大部分优秀的语言模型都没有进行充分的中文预训练,
因此,许多工作都尝试将在英语上表现比较优秀的模型用中文语料进行二次预训练,期望其能够将英语上的优秀能力迁移到中文任务中来。
已经有许多优秀的仓库做过这件事情,比如:[Chinese-LLaMA-Alpaca]。
但在进行正式的训练之前,我们还有一步很重要的事情去做:词表扩充。
通俗来讲,tokenizer 的目的就是将一句话进行切词,并将切好词的列表喂给模型进行训练。
1 | 输入句子 >>> 你好世界 |
通常,tokenizer 有 2 种常用形式:WordPiece 和 BPE。
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,当需要切词的时候就从词表里面查找即可。对于一些多语言模型来讲,要想穷举所有语言中的常用词(穷举不全会造成 OOV)。
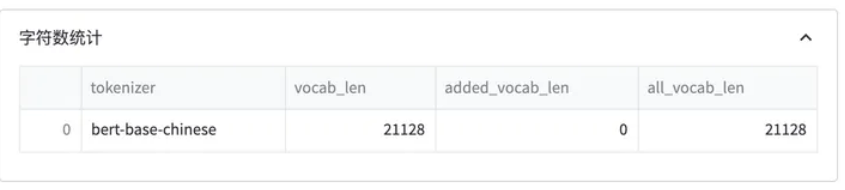
BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。对于中文来讲,一个汉字是由 3 个 unicode 编码组成的
对不在词表中的词拆分成多个token,每个token对应1个unicode编码。
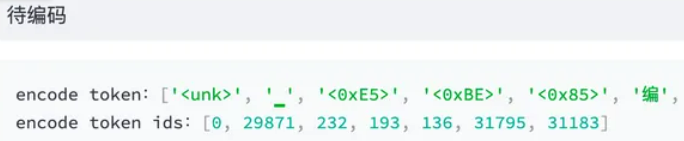
BPE可以避免OOV的情况,但是同样模型训练起来将会更吃力一些。毕竟像「待」这样的汉字特定 unicode 组合其实是不需要模型学习的,但模型却需要通过学习来知道合法的 unicode 序列。
词表扩充:为了降低模型的训练难度,会在原有词表上进行词表扩充。也就是将一些常见的汉字 token 手动添加到原来的 tokenizer 中,从而降低模型的训练难度。
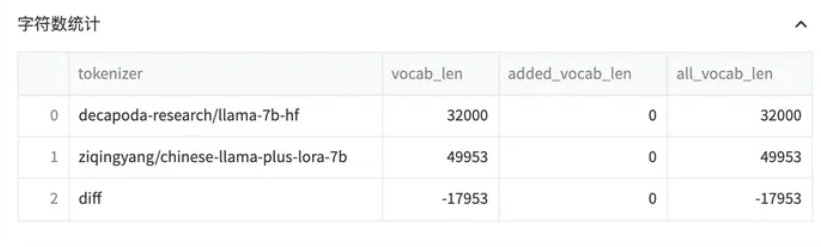
对比 [Chinese-LLaMA] 和 [LLaMA] 之间的 tokenizer 的区别:
1.2 Language Model PreTraining
在扩充完 tokenizer 后,我们就可以开始正式进行模型的预训练步骤了。Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next Token Prediction 的任务,这个很好理解。预训练过程中所用到的方法:数据源采样、数据预处理、模型结构。
- 数据原采样
在 [gpt3] 的训练过程中,存在多个训练数据源,论文中提到:对不同的数据源会选择不同采样比。
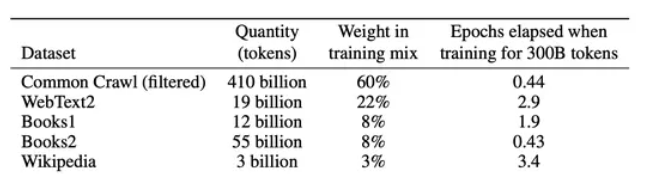
通过「数据源」采样的方式,能够缓解模型在训练的时候受到「数据集规模大小」的影响。从上图中可以看到,相对较大的数据集(Common Crawl)会使用相对较大的采样比例(60%),这个比例远远小于该数据集在整体数据集中所占的规模(410 / 499 = 82.1%),因此,CC 数据集最终实际上只被训练了 0.44(0.6 / 0.82 * (300 / 499))个 epoch。而对于规模比较小的数据集(Wikipedia),则将多被训练几次(3.4 个 epoch)。这样一来就能使得模型不会太偏向于规模较大的数据集,从而失去对规模小但作用大的数据集上的学习信息。
- 数据预处理数据预处理
主要指如何将「文档」进行向量化。通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,但在 Pretrain 任务中,这种方式显得有些浪费。以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
- 模型结构
为了加快模型的训练速度,通常会在 decoder 模型中加入一些 tricks 来缩短模型训练周期。目前大部分加速 tricks 都集中在 Attention 计算上(如:MQA 和 Flash Attention [falcon] 等);此外,为了让模型能够在不同长度的样本上都具备较好的推理能力,通常也会在 Position Embedding 上进行些处理,选用 ALiBi([Bloom])或 RoPE([GLM-130B])等。
- Warmup & Learning Ratio 设置
在继续预训练中,我们通常会使用 warmup 策略,此时我们按照 2 种不同情况划分:
- 当训练资源充足时,应尽可能选择较大的学习率以更好的适配下游任务;
- 当资源不充足时,更小的学习率和更长的预热步数或许是个更好的选择。
1.3 数据集清洗
中文预训练数据集可以使用 [悟道],主要以百科、博客为主。但开源数据集可以用于实验,如果想突破性能,则需要我们自己进行数据集构建。在 [falcon paper] 中提到,仅使用「清洗后的互联网数据」就能够让模型比在「精心构建的数据集」上有更好的效果。
1.4 模型效果评测
关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC] 等,可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理。这种方式可以用来评估模型对「语言模板」的拟合程度,即给定一段话,预测后面可能出现哪些合法的、通顺的字词。但仅仅是「生成通顺句子」的能力现在已经很难满足现在人们的需求,大部分 LLM 都具备生成流畅和通顺语句能力,很难比较哪个好,哪个更好。为此,需要一个能够评估大模型重要能力的的方式——知识蕴含能力评估(C-Eval)。
一个很好的中文知识能力测试数据集是 [C-Eval],涵盖1.4w 道选择题,共 52 个学科。
2.指令微调阶段(Instruction Tuning Stage)
在完成第一阶段的预训练后,就可以开始进到指令微调阶段了。由于预训练任务的本质在于「续写」,如:

因为训练大多来自互联网中的数据,我们无法保证数据中只存在存在规范的「一问一答」格式,这就会造成预训练模型通常无法直接给出人们想要的答案。但是,这并不代表预训练模型「无知」,只是需要我们用一些巧妙的「技巧」来引导出答案。

不过,这种需要用户精心设计从而去「套」答案的方式,显然没有那么优雅。既然模型知道这些知识,只是不符合我们人类的对话习惯,那么我们只要再去教会模型「如何对话」就好了。

2.1Self Instruction
既然我们需要去「教会模型说人话」,那么我们就需要去精心编写各式各样人们在对话中可能询问的问题,以及问题的答案。在 [InstructGPT Paper] 中,使用了 1.3w 的数据来对 GPT-3.5 进行监督学习(下图中左 SFT Data):
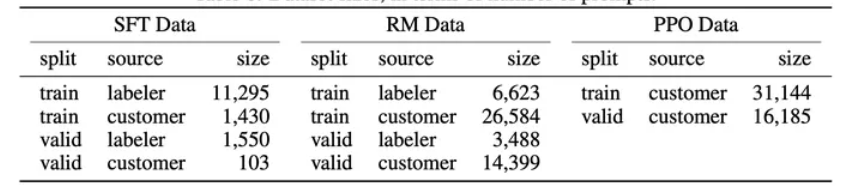
Self Instruction 的思路,即通过 ChatGPT 的输入输出来蒸馏自己的模型。
一个非常出名的项目是 [stanford_alpaca]。如果从 ChatGPT 「套」数据,那么我们至少需要「套」哪些数据。Instruction Tuning 中的「输入」(问题)和「输出」(答案)是训练模型的关键,答案很好得到,喂给 ChatGPT 问题根据返回结果就能获得。Alpaca 则是使用「种子指令(seed)」,使得 ChatGPT 既生成「问题」又生成「答案」。由于 Alpaca 是英文项目,为了便于理解,我们使用相同思路的中文项目 [BELLE作为例子通俗来讲,就是人为的先给一些「训练数据样例」让 ChatGPT 看,紧接着利用 ChatGPT 的续写功能,让其不断地举一反三出新的训练数据集:
1 | 你被要求提供10个多样化的任务指令。这些任务指令将被提供给GPT模型,我们将评估GPT模型完成指令的能力。 |
2.2 开源数据集
已有的指令数据集:
Alpaca:[stanford_alpaca] 采用上述的 self instruction 的方式采集了 5200 条指令训练数据集。
1
2
3
4
5{
"instruction": "Arrange the words in the given sentence to form a grammatically correct sentence.",
"input": "quickly the brown fox jumped",
"output": "The quick brown fox jumped quickly."
}其中,instruction 代表要求模型做的任务,input 代表用户输入, output 代表喂给模型的 label。
BELLE: BELLE 开放了好几种规模的数据集,[100万]、[200万]、[350万] 等。
训练数据集样例如下:
1
2
3
4
5{
"instruction": "判断给定的文章是否符合语法规则。如果不符合,请提供修改建议。 下面是一篇文章的开头: ‘为了探讨这个主题,本文将提供一系列数据和实例,以证明这一观点。’",
"input": "",
"output": "这个开头符合语法规则。"
}
训练数据集中同样包含:摘要、问答、分类等任务。
2.3 模型的评测方法
比起预训练(Pretrain)环节里相对明确的评价指标(如PPL、NLL等),Instruction 环节中的评价指标比较令人头疼。鉴于语言生成模型的发展速度,BLEU 和 ROUGH 这样的指标已经不再客观。一种比较流行的方式是像 [FastChat] 中一样,利用 GPT-4 为模型的生成结果打分。具体是对每个任务单独进行了统计,并在最后一列求得平均值。GPT-4 会对每一条测试样本的 2 个答案分别进行打分,并给出打分理由:
GPT-4 打出的分数和给出理由并不一定正确。最近陆陆续续的推出了许多新的评测方法,如:[PandaLM],
以及许多比较有影响力的评测集,如:[C-Eval]、[open_llm_leaderboard] 等。
3.奖励模型(Reward Model)
3.1 奖励模型(Reward Model)的必要性
在做完 SFT 后,我们大概率已经能得到一个还不错的模型。但整个过程都是在告诉模型什么是[好]的数据,却没有给出[不好]的数据。实际中更倾向于 SFT 的目的只是将 Pretrained Model 中的知识给引导出来的一种手段,而在SFT 数据有限的情况下,我们对模型的「引导能力」就是有限的。这将导致预训练模型中原先「错误」或「有害」的知识没能在 SFT 数据中被纠正,从而出现「有害性」或「幻觉」的问题。为此,一些让模型脱离昂贵标注数据,自我进行迭代的方法被提出,比如:[RLHF],[DPO],但无论是 RL 还是 DPO,我们都需要让告知模型什么是「好的数据」,什么是「不好的数据」。
[^RL、DPO]: RL 是直接告诉模型当前样本的(好坏)得分,DPO 是同时给模型一条好的样本和一条坏的样本。
3.2 利用偏序对训练奖励模型
在 OpenAI 的 [Summarization] 和 [InstructGPT] 的论文中,都使用了「偏序对」来训练模型。偏序对是指:不直接为每一个样本直接打分,而是标注这些样本的好坏顺序。
[^偏序法]: 直接打分:A句子(5分),B句子(3分) 偏序对标注:A > B
模型通过尝试最大化「好句子得分和坏句子得分之间的分差」,从而学会自动给每一个句子判分。
在偏序训练环节,5w 以上的偏序对可能是一个相对保险的量级。
判分任务要比生成认为简单一些,因此可以用稍小一点的模型来作为 RM。
4.强化任务
在获得了一个 Reward Model 后,我们便可以利用这个 RM 来进化我们的模型。目前比较主流的优化方式有 3 种:BON,DPO 和 PPO。
4)大模型的微调(下游任务)
参考:大模型LLM-微调经验分享&总结 - 知乎 (zhihu.com)
已有大模型以及经过了上述这些步骤或者其他操作得到了适用于特定场合的特定模型与权重。如果现在需要将这些模型进行移植,则需要对模型进行微调。一般情况下,模型都不会直接选择微调,主要因为:
1.参数多,内存不容易放下 ;
2.参数多,需要对应更大数据;
3.参数多,不容易收敛;
4.参数多,调参时间过长。
因此需要常见的一些微调方式:
Freeze方法
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
微调代码,见finetuning_freeze.py,核心部分如下:
1 | for name, param in model.named_parameters(): |
PT方法(详见P-tuning:自动构建模版,释放语言模型潜能 - 知乎 (zhihu.com))
PT方法,即P-Tuning方法,参考ChatGLM官方代码 ,是一种针对于大模型的soft-prompt方法。
- P-Tuning,仅对大模型的Embedding加入新的参数。
- P-Tuning-V2,将大模型的Embedding和每一层前都加上新的参数。
1 | config = ChatGLMConfig.from_pretrained(args.model_dir) |
当prefix_projection为True时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;为False时,为P-Tuning方法,仅在大模型的Embedding上新的参数。
Lora方法(详见LORA:大模型轻量级微调 - 知乎 (zhihu.com))
Lora方法,即在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取较好的结果。
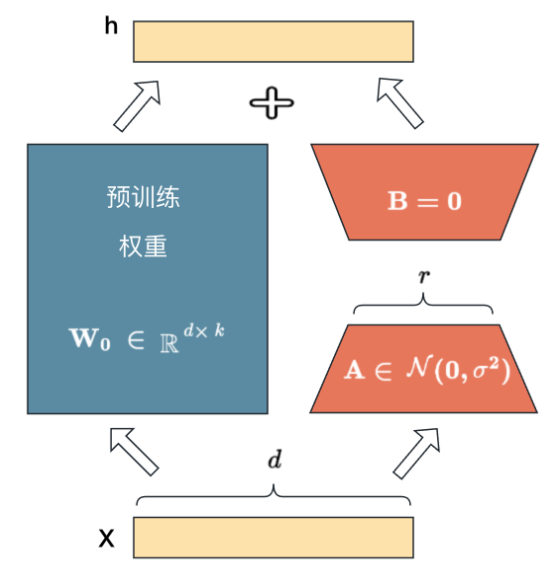
核心部分如下:
1 | model = ChatGLMForConditionalGeneration.from_pretrained(args.model_dir) |
5)下游任务实操
参考:保姆级教程,用PyTorch和BERT进行文本分类 - 知乎 (zhihu.com)
先跑起来,再微调,最后部署
下载模型:
BERT 预训练模型的下载有许多方式,比如从github官网上下载(官网下载的是tensorflow版本的),还可以从源码中找到下载链接,然后手动下载,最后还可以从huggingface中下载。
从huggingface下载预训练模型的地址:https://huggingface.co/models
在搜索框搜索到你需要的模型。
来下载页面
国内速度较慢,可以使用镜像文件下载。
基本使用用例:
1 | from transformers import BertModel,BertTokenizer |
预处理数据
基本熟悉了 BERT 的基本使用,接下来为其准备输入数据。一般情况下,在训练模型前,都需要对手上的数据进行预处理,以满足模型需要。
模型输入数据中,需要通过添加 [CLS] 和 [SEP] 这两个特殊的token,将文本转换为 BERT 所期望的格式。
首先,需要通过 pip 安装 Transformers 库:
1 | !pip install transformers |
为了更容易理解得到的输出tokenization,我们以一个简短的文本为例。
1 | from transformers import BertTokenizer |
下面是对上面BertTokenizer参数的解释:
padding:将每个sequence填充到指定的最大长度。max_length: 每个sequence的最大长度。本示例中我们使用 10,但对于本文实际数据集,我们将使用 512,这是 BERT 允许的sequence 的最大长度。truncation:如果为True,则每个序列中超过最大长度的标记将被截断。return_tensors:将返回的张量类型。由于我们使用的是 Pytorch,所以我们使用pt;如果你使用 Tensorflow,那么你需要使用tf。
从上面的变量中看到的输出bert_input,是用于稍后的 BERT 模型。但是这些输出是什么意思?
第一行是 input_ids,它是每个 token 的 id 表示。实际上可以将这些输入 id 解码为实际的 token,如下所示:
1 | example_text = tokenizer.decode(bert_input.input_ids[0]) |
由上述结果所示,BertTokenizer负责输入文本的所有必要转换,为 BERT 模型的输入做好准备。它会自动添加 [CLS]、[SEP] 和 [PAD] token。由于我们指定最大长度为 10,所以最后只有两个 [PAD] token。
第二行是 token_type_ids,它是一个 binary mask,用于标识 token 属于哪个 sequence。如果我们只有一个 sequence,那么所有的 token 类型 id 都将为 0。对于文本分类任务,token_type_ids是 BERT 模型的可选输入参数。
第三行是 attention_mask,它是一个 binary mask,用于标识 token 是真实 word 还是只是由填充得到。如果 token 包含 [CLS]、[SEP] 或任何真实单词,则 mask 将为 1。如果 token 只是 [PAD] 填充,则 mask 将为 0。
注意到,我们使用了一个预训练BertTokenizer的bert-base-cased模型。如果数据集中的文本是英文的,这个预训练的分词器就可以很好地工作。
如果有来自不同语言的数据集,可能需要使用bert-base-multilingual-cased。具体来说,如果你的数据集是德语、荷兰语、中文、日语或芬兰语,则可能需要使用专门针对这些语言进行预训练的分词器。可以在此处查看相应的预训练标记器的名称。特别地,如果数据集中的文本是中文的,需要使用bert-base-chinese 模型,以及其相应的BertTokenizer等。
数据集
现在我们知道从BertTokenizer中获得什么样的输出,接下来为新闻数据集构建一个Dataset类,该类将作为一个类来将新闻数据转换成模型需要的数据格式。
1 | import torch |
在上面实现的代码中,我们定义了一个名为 labels的变量,它是一个字典,将DataFrame中的 category 映射到 labels的 id 表示。注意,上面的__init__函数中,还调用了BertTokenizer将输入文本转换为 BERT 期望的向量格式。
定义Dataset类后,将数据框拆分为训练集、验证集和测试集,比例为 80:10:10。
1 | import pandas as pd |
构建模型
至此,我们已经成功构建了一个 Dataset 类来生成模型输入数据。现在使用具有 12 层 Transformer 编码器的预训练 BERT 基础模型构建实际模型。
如果数据集中的文本是中文的,需要使用bert-base-chinese 模型。
1 | from torch import nn |
从上面的代码可以看出,BERT 模型输出了两个变量:
- 在上面的代码中命名的第一个变量
_包含sequence中所有 token 的 Embedding 向量层。 - 命名的第二个变量
pooled_output包含 [CLS] token 的 Embedding 向量。对于文本分类任务,使用这个 Embedding 作为分类器的输入就足够了。
然后将pooled_output变量传递到具有 ReLU 激活函数的线性层。在线性层中输出一个维度大小为 5 的向量,每个向量对应于标签类别(运动、商业、政治、 娱乐和科技)。
训练模型
接下来是训练模型。使用标准的 PyTorch 训练循环来训练模型。
1 | from torch.optim import Adam |
我们对模型进行了 5 个 epoch 的训练,我们使用 Adam 作为优化器,而学习率设置为1e-6。因为本案例中是处理多类分类问题,则使用分类交叉熵作为我们的损失函数。
建议使用 GPU 来训练模型,因为 BERT 基础模型包含 1.1 亿个参数。
1 | EPOCHS = 5 |
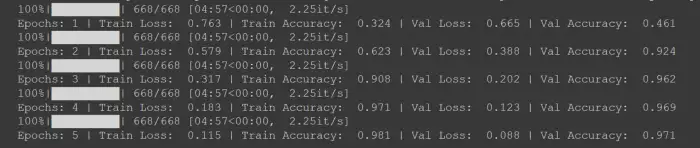
显然,由于训练过程的随机性,每次可能不会得到与上面截图类似的损失和准确率值。如果在 5 个 epoch 之后没有得到好的结果,可以尝试将 epoch 增加到 10 个,或者调整学习率。
在测试数据上评估模型
现在我们已经训练了模型,我们可以使用测试数据来评估模型在未见数据上的性能。下面是评估模型在测试集上的性能的函数。
1 | def evaluate(model, test_data): |
运行上面的代码后,我从测试数据中得到了 0.991的准确率。由于训练过程中的随机性,将获得的准确度可能会与我的结果略有不同。
2023开源大语言模型
| 模型名 | 参数量 | 用处 | 论文 |
|---|---|---|---|
| SAIL 7B | 7B | 基于LLaMa的搜索增强 | SAIL — Search Augmented Instruction Learning |
| Guanaco | 65B | 采用高效微调方法QLoRA发布的LLM模型 | QLoRA — Efficient Finetuning of Quantized LLMs |
| RMKV | 100M–14B | 与transformer的LLM性能相当的RNN模型 | Scaling RNN to 1.5B and Reach Transformer LM Performance |
| MPT-7B | 7B | MosaicML的基础系列模型 | MPT-7B — A New Standard for Open-Source, Commercially Usable LLMs |
| OpenLLaMa | 3B,7B | 在RedPajama数据集上训练的Meta AI的LLaMA 7B的另一个开源复制。 | Meet OpenLLaMA — An Open-Source Reproduction of Meta AI’s LLaMA Large Language Model |
| RedPajama-INCITE | 3B,7B | 基于RedPajama数据集上训练的指令调整和聊天Pythia模型。 | RedPajama-INCITE family of models including base, instruction-tuned & chat models |
| h2oGPT | 12B,30B | H2O的微调框架和文档问答功能的聊天机器人UI | Building the World’s Best Open-Source Large Language Model: H2O.ai’s Journey |
| FastChat-T5 | 3B | 通过微调Flan-t5-xl对从ShareGPT收集的用户共享对话进行训练的聊天机器人 | FastChat-T5 — our compact and commercial-friendly chatbot! |
| GPT4All | 7–13B | 用于训练和部署强大的定制llm的完整工具系统 | GPT4All: An ecosystem of open-source on-edge large language models. |
| MiniGPT-4 | 13B | 基于BLIP-2和Vicuna LLM的Visual LLM模型 | MiniGPT-4 — Enhancing Vision-Language Understanding withAdvanced Large Language Models |
| StableLM | 7B | StableLM的LLM模型系列 | Stability AI Launches the First of its StableLM Suite of Language Models |
| BloomZ | 176B | 通过多任务微调实现跨语言泛化 | Cross-lingual Generalization through Multitask Finetuning |
| Dolly | 12B | Pythia 12B LLM在Databricks ML平台上训练的模型 | Free Dolly — Introducing the World’s First Truly Open Instruction-Tuned LLM |
| Baize Chatbot | 30B | 基于LLaMa的开源聊天模型 | Baize — An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data |
| ColossalChat | N/A | 由ColossalAI开源发布的一个完整的RLHF流程训练的模型 | ColossalChat — An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline |
| Lit LLaMa | 13B | 来自Lightning AI的LLaMA的开源实现 | Why We’re Building Lit-LLaMA |
| Cerebras-GPT | 111M-13B | 开放的,计算效率高的,大型语言模型 | Cerebras-GPT — Open Compute-Optimal Language ModelsTrained on the Cerebras Wafer-Scale Cluster |
| Open Flamingo | 9B | Deepmind的Flamingo模型的开源实现 | Openflamingo — An Open-source Framework For Training Vision-language Models With In-context Learning |
| Chat GLM | 6B-130B | 使用开放式双语(中英文)双向密集预训练模型 | GLM-130B: An Open Bilingual Pre-trained Model |
| DLite | 124M | 通过微调Alpaca数据集上最小的GPT-2模型 | Introducing DLite, a Lightweight ChatGPT-Like Model Based on Dolly |
| Alpaca 7B | 7B | 描述:斯坦福大学发布的指令遵循LLaMA模型 | Alpaca — A Strong, Replicable Instruction-Following Model |
| Flan UL2 | 20B | 在预训练的UL2检查点上训练Flan 20B模型。 | A New Open Source Flan 20B with UL2 |
| Flan-T5 | 60M–11B | T5在各种数据集上的指令微调,提高预训练语言模型的可用性 | Scaling Instruction-Finetuned Language Models |
视觉大模型扩展
参考:万字长文带你全面解读视觉大模型 - 知乎 (zhihu.com)
上述内容描述的是大型语言模型(LLMs),同样视觉系统对于理解和推理视觉场景的组成特性至关重要。这个领域的挑战在于对象之间的复杂关系、位置、歧义、以及现实环境中的变化等。
视觉大模型的介绍
大型语言模型(LLMs)取得成功的原有主要归于数据和模型规模的大幅扩展。例如,像GPT-3这样的十亿参数模型已成功用于零/少样本学习,而无需大量的任务特定数据或模型参数更新。与此同时,有5400亿参数的Pathways Language Model(PaLM)在许多领域展现了先进的能力,包括语言理解、生成、推理和与代码相关的任务。
同样在视觉领域,诸如CLIP这样的预训练视觉语言模型在不同的下游视觉任务上展现了强大的零样本泛化性能。这些模型通常使用从网络收集的数百上千万图像-文本对进行训练,并提供具有泛化和迁移能力的表示。因此,只需通过简单的自然语言描述和提示,这些预训练的基础模型完全被应用到下游任务。如下图所示:
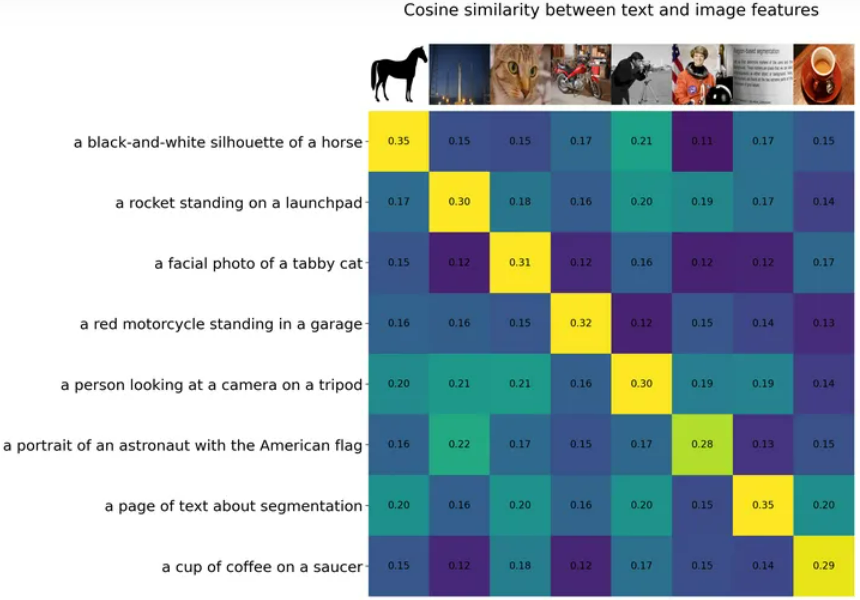
大型视觉语言基础模型外,一些研究工作也致力于开发可以通过视觉输入提示的大型基础模型。例如,最近 META 推出的 SAM 能够执行与类别无关的分割,给定图像和视觉提示(如框、点或蒙版),指定要在图像中分割的内容。这样的模型可以轻松适应特定的下游任务,如医学图像分割、视频对象分割、机器人技术和遥感等。

当然,我们同样可以将多种模态一起串起来,组成更有意思的管道,如RAM+Grounding-DINO+SAM:

这里使用 RAM 提取了图像的语义标签,再通过将标签输入到 Grounding-DINO 中进行开放世界检测,最后再通过将检测作为 SAM 的提示分割一切。目前视觉基础大模型可以粗略的归为三类:
textually prompted models(文本提示的模型), e.g., contrastive, generative, hybrid, and conversational;visually prompted models(视觉提示的模型), e.g., SAM, SegGPT;heterogeneous modalities-based models(综合性基础模型), e.g., ImageBind, Valley
后面会进行一个详细的模型分类。
视觉大模型的训练
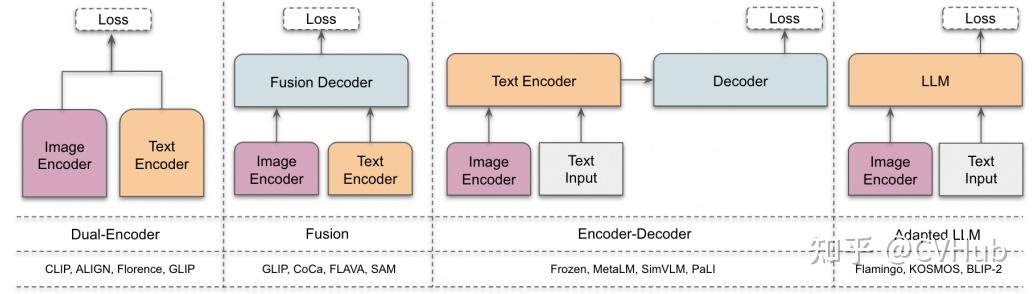
基础架构
- 双编码器架构:其中,独立的编码器用于处理视觉和文本模态,这些编码器的输出随后通过目标函数进行优化。
- 融合架构:包括一个额外的融合编码器,它获取由视觉和文本编码器生成的表示,并学习融合表示。
- 编码器-解码器架构:由基于编码器-解码器的语言模型和视觉编码器共同组成。
- 自适应 LLM 架构:利用大型语言模型(LLM)作为其核心组件,并采用视觉编码器将图像转换为与 LLM 兼容的格式(模态对齐)。
目标函数
- 对比式学习
为了从无标签的图像-文本数据中学习,CLIP 中使用了简单的图像-文本对比(ITC)损失来通过学习正确的图像-文本配对来学习表示。此外还有图像-文本匹配(ITM)损失,以及包括简单对比式学习表示(SimCLR)和 ITC 损失的变体(如 FILIP Loss、TPC Loss、RWA、MITC、UniCL、RWC 损失)等其他对比损失。
通俗的讲就是计算图像与文本之间的相似度得分,比如常见的余弦相似性。
- 生成式学习

以及 Flamingo Loss、Prefix Language Modeling, PrefixML 等。从上述公式我们也可以很容易看出,生成式 AI 本质还是条件概率模型,如 Cap 损失便是根据上一个已知 token 或 图像来预测下一个 token。
预训练
数据集:
视觉-语言基础模型的核心是大规模数据,大致可分为几类:
- 图像-文本数据:例如
CLIP使用的WebImageText等,这些数据通常从网络抓取,并经过过滤过程删除噪声、无用或有害的数据点。 - 部分伪标签数据:由于大规模训练数据在网络上不可用,收集这些数据也很昂贵,因此可以使用一个好的教师将图像-文本数据集转换为掩码-描述数据集,如
GLIP和SA-1B等。 - 数据集组合:有些工作直接将基准视觉数据集组合使用,这些作品组合了具有图像-文本对的数据集,如字幕和视觉问题回答等。一些工作还使用了非图像-文本数据集,并使用基于模板的提示工程将标签转换为描述。
微调:
微调主要用于三个基本设置:
- 提高模型在特定任务上的性能(例如开放世界物体检测,
Grounding-DINO); - 提高模型在某一特定能力上的性能(例如视觉定位);
- 指导调整模型以解决不同的下游视觉任务(例如
InstructBLIP)。
首先,许多工作展示,即使只采用线性探测,也可以提高模型在特定任务上的性能。因此,特定任务的数据集(例如ImageNet)是可以用来改善预训练模型的特定任务性能。其次,一些工作已经利用预训练的视觉语言模型,通过在定位数据集上微调模型来进行定位任务。
提示工程:
提示工程主要是搭配大型语言模型(LLMs)一起使用,使它们能够完成某些特定的任务。在视觉语言模型或视觉提示模型的背景下,提示工程主要用于两个目的:
- 将视觉数据集转换为图像文本训练数据(例如,用于图像分类的 CLIP),为基础模型提供交互性
- 使用视觉语言模型进行视觉任务。
大多数视觉数据集由图像和相应文本标签组成。为了利用视觉语言模型处理视觉数据集,一些工作已经利用了基于模板的提示工程。在这种提示工程中,使用一组模板从标签生成描述。
视觉大模型分类
基于文本提示
基于不同的训练目标,文本提示的基础模型主要分为三类:对比学习、生成学习和混合方法。
对比学习
| 模型 | 作用 | 方法与特色 |
|---|---|---|
| CLIP 架构及其衍生的变体(如FLIP、SLIP等) | 联合训练图像和文本编码器以预测图像与标题在批量中的正确配对 | 对比学习,实现万物分类 |
| ALIGN | 同样是图像与标题的配对问题 | 对比学习,超过10亿个图像-文本对的噪声数据集,只要数据库够大,便可以弥补它的噪声,并最终得到 SOTA 结果。 |
| FILIP | 图像与标题的配对问题 | 最大化了视觉和文本嵌入之间逐标记的相似性,捕捉细粒度差异。能够处理不同的空间、时间和模态。预训练参数只有 893M,但需要在 512 块 A100 上训练 10 天的时间。 |
视觉定位基础模型
针对上述模型定位能力较差而提出的视觉定位任务模型
| 模型 | 作用 | 方法与特色 |
|---|---|---|
| RegionCLIP | 零样本目标检测和开放词汇目标检测。 | 扩展了 CLIP 以学习区域级视觉表示,其支持图像区域和文本概念之间的细粒度对齐,从而支持基于区域的推理任务。 |
| CRIS | 各类像素级任务 | 引入视觉-语言解码器和文本到像素对比损失,使 CLIP 框架学习像素级信息 |
| Grounding DINO/OWL-ViT | 目标检测与分割任务 | 利用强大的预训练模型,并通过对比学习进行修改,以增强与语言的对齐。 |
基于生成式的方法
首先是结合大语言模型(Large Language Model, LLM)的多模态学习范式:
- 结合上下文的多模态输入学习:例如
Frozen方法将图像编码器与LLM结合,无需更新LLM的权重,而是在带有图像标注的数据集上训练视觉编码器。类似地,Flamingo模型采用了固定的预训练视觉和语言模型,并通过Perceiver Resampler进行连接。 - 使用LLM作为其它模态的通用接口:如
MetaLM模型采用半因果结构,将双向编码器通过连接层连接到解码器上,可实现多任务微调和指令调整零样本学习。此外,KOSMOS系列也在LLM上整合了多模态学习的能力。 - 开源版本的模型:如
OpenFlamingo,是Flamingo模型的开源版本,训练于新的多模态数据集。
其次我们来看下视觉-语言对齐与定位相关的模型:
- 具备定位能力的模型:
KOSMOS-2通过添加一条管线来抽取文本中的名词短语并将其与图像中的相应区域链接起来,进而实现视觉定位。
另外就是通用生成目标下的训练:
- 简化视觉语言建模:如
SimVLM使用前缀语言建模(PrefixLM)目标进行训练,不需要任务特定的架构或训练,可在多个视觉语言任务上实现优秀的性能。 - 掩码重构与对齐:如
MaskVLM,采用联合掩码重构语言建模,其中一个输入的掩码部分由另一个未掩码输入重构,有效对齐两个模态。 - 模块化视觉语言模型:如
mPLUG-OWL,由图像编码器、图像抽象器和冻结LLM组成,通过两阶段的训练实现多模态对话和理解。
此外还有与对比学习的比较与结合:
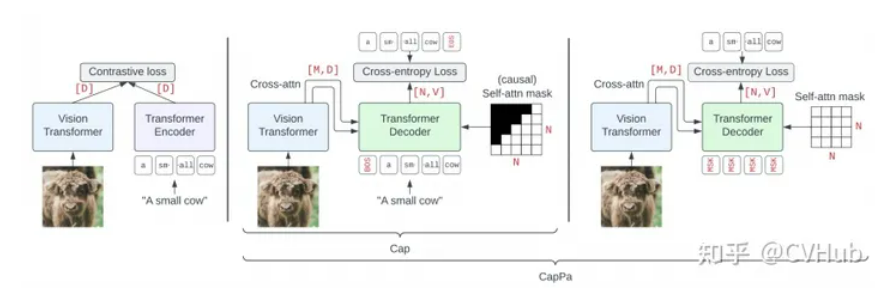
CapPa 是基于字幕的模型与 CLIP 风格模型的比较得到的一种新的生成预训练方法,交替使用自回归预测和并行预测。
总体而言,上述的方法和模型通过在视觉条件下训练语言生成任务,为 LLM 增添了“看世界”的能力。这些工作在视觉语言任务,如图像标注、多模态对话和理解等方面取得了显著进展,有的甚至在少样本情况下达到或超越了最先进的性能。通过将视觉和语言模态结合,这些模型为计算机视觉和自然语言处理的交叉领域提供了强大的新工具。
对比学习与生成式的混合方法
这些方法共同探讨了视觉定位任务的不同维度,包括开放词汇对象检测、通用对象检测、两阶段训练、多级粒度和新颖的损失功能。它们共同通过以创新的方式整合视觉和语言来推动视觉理解的界限,往往超越了该领域以前的基准。
UNITER:结合了生成(例如掩码语言建模和掩码区域建模)和对比(例如图像文本匹配和单词区域对齐)目标的方法,适用于异构的视觉-语言任务。Pixel2Seqv2:将四个核心视觉任务统一为像素到序列的接口,使用编码器-解码器架构进行训练。Vision-Language:使用像 BART 或 T5 等预训练的编码器-解码器语言模型来学习不同的计算机视觉任务Contrastive Captioner (CoCa):结合了对比损失和生成式的字幕损失,可以在多样的视觉数据集上表现良好。FLAVA:适用于单模态和多模态任务,通过一系列损失函数进行训练,以便在视觉、语言和视觉-语言任务上表现良好。BridgeTower:结合了不同层次的单模态解码器的信息,不影响执行单模态任务的能力。PaLI:一种共同扩展的多语言模块化语言-视觉模型,适用于单模态和多模态任务。X-FM:包括语言、视觉和融合编码器的新基础模型,通过组合目标和新技术进行训练。BLIP:利用生成和理解能力有效利用图像文本数据集,采用Multimodal mixture of Encoder-Decoder (MED)架构。BLIP-2:通过查询转换器来实现计算效率高的模态间对齐InstructBLIP:利用视觉编码器、Q-Former和LLM,通过指令感知的视觉特征提取来进行训练。 对预训练模型的高效利用:VPGTrans:提供了一种高效的方法来跨 LLM 传输视觉编码器。TaCA:提到了一种叫做TaCA的适配器,但没有进一步详细描述。ViLD: 这一方法使用了一个两阶段的开放词汇对象检测系统,从预训练的单词汇分类模型中提取知识。它包括一个RPN和一个类似于CLIP的视觉语言模型,使用Mask-RCNN创建对象提案,然后将知识提取到对象检测器中。UniDetector: 此方法旨在进行通用对象检测,以在开放世界中检测新的类别。它采用了三阶段训练方法,包括类似于上面我们提到的RegionCLIP的预训练、异构数据集训练以及用于新类别检测的概率校准。UniDetector 为大词汇和封闭词汇对象检测设立了新的标准。X-Decoder: 在三个粒度层次(图像级别、对象级别和像素级别)上运作,以利用任务协同作用。它基于Mask2Former,采用多尺度图像特征和两组查询来解码分割掩码,从而促进各种任务。它在广泛的分割和视觉语言任务中展现出强大的可转移性
总结:上面展示了如何通过对比和生成式学习,以及混合这些方法,来设计和训练可以处理各种视觉和语言任务的模型。有些模型主要关注提高单模态和多模态任务的性能,而有些模型关注如何高效地训练和利用预训练模型。总的来说,这些研究提供了视觉-语言融合研究的丰富视角和多样化方法,以满足不同的实际需求和应用场景。
基于对话式的视觉模型
基于对话的视觉语言模型在理解、推理和进行人类对话方面取得了显著进展。通过将视觉和语言结合在一起,这些模型不仅在传统 NLP 任务上表现出色,而且能够解释复杂的视觉场景,甚至能够与人类进行复杂的多模态对话。未来可能会有更多的工作致力于提高这些模型的可解释性、可用性和可访问性,以便在更广泛的应用领域中实现其潜力。主要模型如下:
GPT-4:这是首个结合视觉和语言的模型,能够进行多模态对话。该模型基于Transformer架构,通过使用公开和私有数据集进行预训练,并通过人类反馈进行强化学习微调。根据公开的数据,GPT-4 在多个 NLP、视觉和视觉-语言任务上表现出色,但很可惜目前并未开源。
miniGPT-4: 作为GPT-4的开源版本,miniGPT-4 由预训练的大型语言模型Vicuna和视觉组件ViT-G和Q-Former组成。模型先在多模态示例上进行训练,然后在高质量的图像和文本对上进行微调。miniGPT-4 能够生成复杂的图像描述并解释视觉场景。
XrayGPT: 这个模型可以分析和回答有关 X 射线放射图的开放式问题。使用Vicuna LLM作为文本编码器和MedClip作为图像编码器,通过更新单个线性投影层来进行多模态对齐。
LLaVA: 这是一个开源的视觉指令调整框架和模型,由两个主要贡献组成:开发一种用于整理多模态指令跟踪数据的经济方法,以及开发一个大型多模态模型,该模型结合了预训练的语言模型LLaMA和CLIP的视觉编码器
LLaMA-Adapter V2: 通过引入视觉专家,早期融合视觉知识,增加可学习参数等方式,改善了LLaMA的指令跟随能力,提高了在传统视觉-语言任务上的性能。
基于视觉提示
CLPSeg:概述:CLIPSeg 利用 CLIP 的泛化能力执行 zero-shot 和 one-shot 分割任务。结构:由基于 CLIP 的图像和文本编码器以及具有 U-net 式跳跃连接的基于 Transformer 的解码器组成。工作方式:视觉和文本查询通过相应的 CLIP 编码器获取嵌入,然后馈送到 CLIPSeg 解码器。因此,CLIPSeg 可以基于任意提示在测试时生成图像分割.
SegGPT 旨在训练一个通用模型,可以用于解决所有的分割任务,其训练被制定为一个上下文着色问题,为每个数据样本随机分配颜色映射。目标是根据上下文完成不同的分割任务,而不是依赖于特定的颜色。
SAM :概述:SAM 是一种零样本分割模型,从头开始训练,不依赖于 CLIP。 结构:使用图像和提示编码器对图像和视觉提示进行编码,然后在轻量级掩码解码器中组合以预测分割掩码。 训练方法:通过三阶段的数据注释过程(辅助手动、半自动和全自动)训练。
SEEM 有一个统一的提示编码器,将所有视觉和语言提示编码到联合表示空间中。因此,SEEM 可以支持更通用的用途。它有潜力扩展到自定义提示。其次,SEEM 在文本掩码(基础分割)方面非常有效,并输出语义感知预测。SEEM 涵盖了更广泛的交互和语义层面。例如,SAM 只支持有限的交互类型,如点和框,而由于它本身不输出语义标签,因此错过了高语义任务。
特别的基于SAM有很多下游任务的实现比如:
- 医疗
MedSAM:通过在大规模医学分割数据集上微调 SAM,创建了一个用于通用医学图像分割的扩展方法 MedSAM。这一方法在 21 个 3D 分割任务和 9 个 2D 分割任务上优于 SAM。
AutoSAM:为SAM的提示生成了一个完全自动化的解决方案,基于输入图像由AutoSAM辅助提示编码器网络生成替代提示。AutoSAM 与原始的 SAM 相比具有更少的可训练参数。
Adapting Through Adapters:在眼科的多目标分割,通过学习新的可学习的提示层对SAM进行了一次微调,从而准确地分割不同的模态图像中的血管或病变或视网膜层。
3DSAM-adapter:为了适应3D空间信息,提出了一种修改图像编码器的方案,使原始的2D变换器能够适应体积输入。
Medical SAM Adapter:专为SAM设计了一个通用的医学图像分割适配器,能够适应医学数据的高维度(3D)以及独特的视觉提示,如 point 和 box。
DeSAM:提出了将 SAM 的掩码解码器分成两个子任务:提示相关的 IoU 回归和提示不变的掩码学习。DeSAM 最小化了错误提示在“分割一切”模式下对SAM性能的降低。
MedLAM:提出了一个使用 SAM 的医学数据集注释过程,并引入了一个少量定位框架。MedLAM 显著减少了注释负担,自动识别整个待注释数据集的目标解剖区域。
Segment Any Medical Model, SAMM:这是一个结合了3D Slicer和SAM的医学图像分割工具,协助开发、评估和应用SAM。通过与3D Slicer的整合,研究人员可以使用先进的基础模型来分割医学图像。
总体来说,通过各种微调、适配和修改方法,SAM 已被成功适应了用于医学图像分割的任务,涵盖了从器官、病变到组织的不同医学图像。这些方法也突出了将自然图像的深度学习技术迁移到医学领域的潜力和挑战。在未来,SAM 及其变体可能会继续推动医学图像分析领域的进展。
- 场景识别和追踪
SAM 在跟踪任务方面的应用集中在通过视频中的帧跟踪和分割任意对象,通常被称为视频对象分割(VOS)。这个任务涉及在一般场景中识别和追踪感兴趣的区域。以下总结下 SAM 在跟踪方面的一些主要应用和方法:
Segment Any Medical Model, SAMM:概述:TAM 使用 SAM 和现成的跟踪器 XMem 来分割和跟踪视频中的任何对象。 操作方式:用户可以简单地点击一个对象以初始化 SAM 并预测掩码。然后,XMem 使用 SAM提供的初始掩码预测在视频中基于时空对应关系跟踪对象。用户可以暂停跟踪过程并立即纠正任何错误。 挑战:虽然表现良好,但 TAM 在零样本场景下不能有效保留 SAM 的原始性能。
SAM-Track:概述:与 TAM 类似,SAM-Track 使用 DeAOT 与 SAM 结合。 挑战:与 TAM 类似,SAM-Track 在零样本场景下也存在性能挑战。
…很有很多其他领域的模型,比如遥感、字幕等,此处不一一赘述。
综合性基础模型
CLIP2Video:这一模型扩展了CLIP模型,使其适用于视频。通过引入时序一致性和提出的时序差异块(TDB)和时序对齐块(TAB),将图像-文本的CLIP模型的空间语义转移到视频-文本检索问题中。
AudioCLIP:这一模型扩展了CLIP,使其能够处理音频。AudioCLIP结合了ESResNeXt音频模型,并在训练后能够同时处理三种模态,并在环境声音分类任务中胜过先前方法。
Image Bind:这一模型通过学习配对数据模态(如(视频,音频)或(图像,深度))的共同表示,包括多种模态。ImageBind 将大规模配对数据(图像,文本)与其他配对数据模态相结合,从而跨音频、深度、热和惯性测量单元(IMU)等四种模态扩展零样本能力。
COSA:通****过将图像-文本语料库动态转换为长篇幅视频段落样本来解决视频所需的时序上下文缺失问题。通过随机串联图像-文本训练样本,确保事件和句子的显式对应,从而创造了丰富的场景转换和减少视觉冗余。
Valley: 是另一个能够整合视频、图像和语言感知的多模态框架。通过使用简单的投影模块来桥接视频、图像和语言模态,并通过指令调谐流水线与多语言 LLM 进一步统一。
Palm-E:该模型将连续的传感器输入嵌入到 LLM 中,从而允许机器人进行基于语言的序列决策。通过变换器,LLM将图像和状态估计等输入嵌入到与语言标记相同的潜在空间,并以相同的方式处理它们。
ViMA:使用文本和视觉提示来表达一系列机器人操控任务,通过多模态提示来学习机器人操控。它还开发了一个包含600K专家轨迹的模拟基准测试,用于模仿学习。
MineDojo:为 Minecraft 中的开放任务提供了便利的API,并收集了丰富的 Minecraft 数据。它还使用这些数据为体现代理制定了新的学习算法。
VOYAGER:这是一种由 LLM 驱动的终身学习代理,设计用于在 Minecraft 中探索、磨练技能并不断发现新事物。它还通过组合较小的程序逐渐构建技能库,以减轻与其他持续学习方法相关的灾难性遗忘。
LM-Nav:结合预训练的视觉和语言模型与目标控制器,从而在目标环境中进行长距离指导。通过使用视觉导航模型构建环境的“心理地图”,使用 GPT-3 解码自由形式的文本指示,并使用 CLIP将这些文本地标连接到拓扑图中,从而实现了这一目标。然后,它使用一种新的搜索算法找到了机器人的计划。
总体而言,基于代理的基础视觉模型突出了语言模型在现实世界任务中的潜力,如机器人操作、持续学习和复杂导航。它们不仅推动了机器人技术的进展,还为自然语言理解、多模态交互和现实世界应用开辟了新的研究方向。通过将预训练的大型语言模型与机器人技术和视觉导航相结合,基于代理的基础视觉模型能够解决现实世界中的复杂任务,展示了人工智能的跨学科整合和应用潜力。