本文包括多个IP核的学习,如:MMCM/PLL、RAM、ROM、FIFO。
PLL核
PLL 的英文全称是 Phase Locked Loop,即锁相环,是一种反馈控制电路。PLL 对时钟网络进行系统级的时钟管理和偏移控制,具有时钟倍频、分频、相位偏移和可编程占空比的功能。Xilinx 7 系列器件中的时钟资源包含了时钟管理单元 CMT,每个 CMT 由一个 MMCM 和一个 PLL 组成。对于一个简单的设计来说,FPGA 整个系统使用一个时钟或者通过编写代码的方式对时钟进行分频是可以完成的,但是对于稍微复杂一点的系统来说,系统中往往需要使用多个时钟和时钟相位的偏移,且通过编写代码输出的时钟无法实现时钟的倍频,因此学习 Xilinx MMCM/PLL IP 核的使用方法是我们学习 FPGA 的一个重要内容。本章我们将通过一个简单的例程来向大家介绍一下 MMCM/PLL IP 核的使用方法。
IP核调用
我们首先创建一个空的工程,工程名为“ip_clk_wiz”。接下来添加 PLL IP 核。在 Vivado 软件的左侧“Flow Navigator”栏中单击“IP Catalog”,“IP Catalog”按钮以及单击后弹出的“IP Catalog”窗口如下图所示。
打开“IP Catalog”窗口后,在搜索栏中输入“clock”关键字,可以看到 Vivado 已经自动查找出了与关键字匹配的 IP 核名称,如下图所示。
我们双击“FPGA Features and Design”→“Clocking”下的“Clocking Wizard”,弹出“Customize IP”窗口,如下图所示。
接下来就是配置 IP 核的时钟参数。最上面的“Component Name”一栏设置该 IP 元件的名称,这里保持默认即可。在第一个“Clocking Options”选项卡中,“Primitive”选项用于选择是使用 MMCM 还是 PLL 来输出不同的时钟,对于我们的本次实验来说,MMCM 和 PLL 都可以完成,这里我们可以保持默认选择MMCM。需要修改的是最下面的“Input Clock Information”一栏,把“Primary”时钟的输入频率修改为我们开发板的核心板上的晶振频率 50MHz,其他的设置保持默认即可,如下图所示。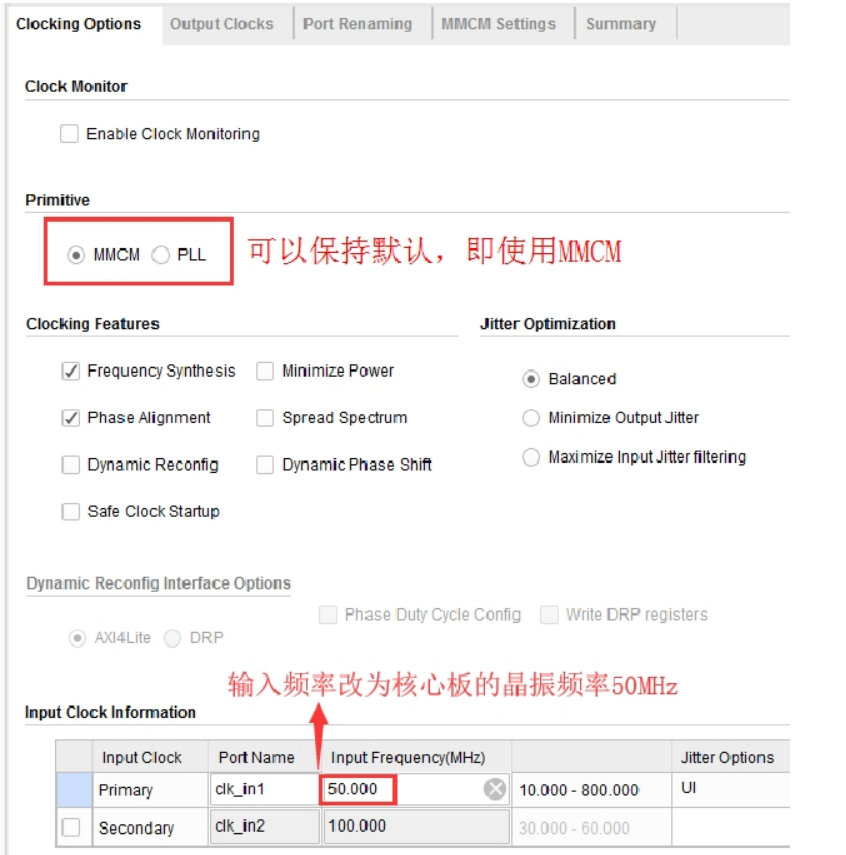
接下来切换至“Output Clocks”选项卡,在“Output Clock”选项卡中,勾选前 4 个时钟,并且将其“Output Freq(MHz)”分别设置为 100、100、50、25,注意,第 2 个 100MHz 时钟的相移“Phase(degrees)”一栏要设置为 180。其他设置保持默认即可,如下图所示。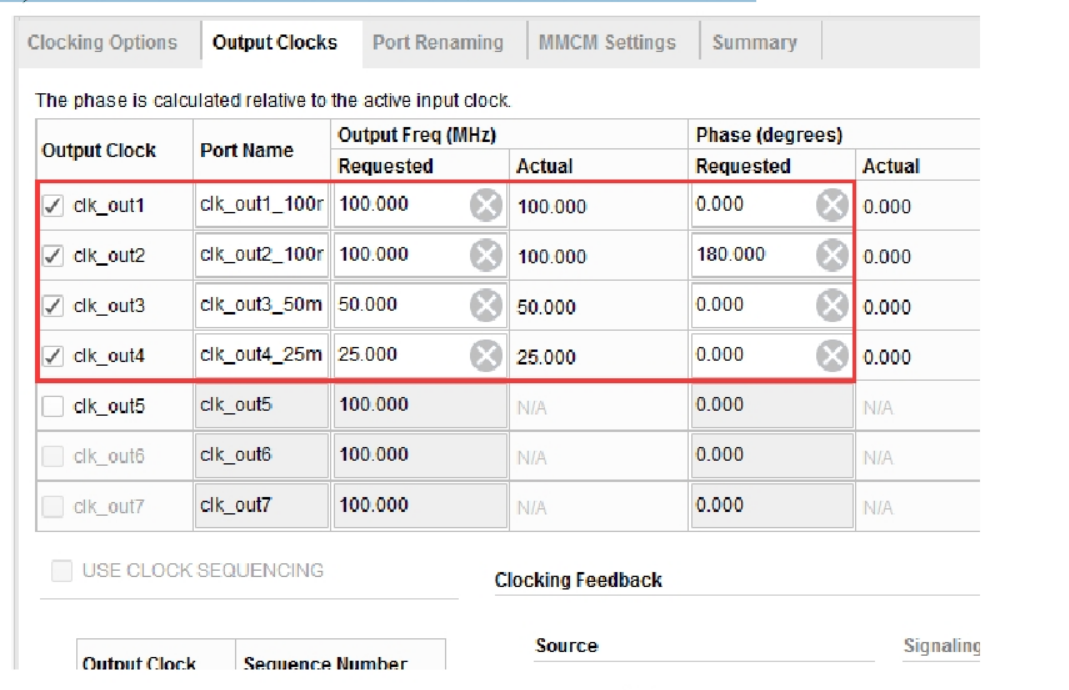
Port Renaming”选项卡主要是对一些控制信号的重命名。这里我们只用到了锁定指示 locked 信号,其名称保持默认即可,如下图所示。
“MMCM Setting”选项卡展示了对整个 MMCM/PLL 的最终配置参数,这些参数都是根据之前用户输入的时钟需求由 Vivado 来自动配置,Vivado 已经对参数进行了最优的配置,在绝大多数情况下都不需要用户对它们进行更改,也不建议更改,所以这一步保持默认即可,如下图所示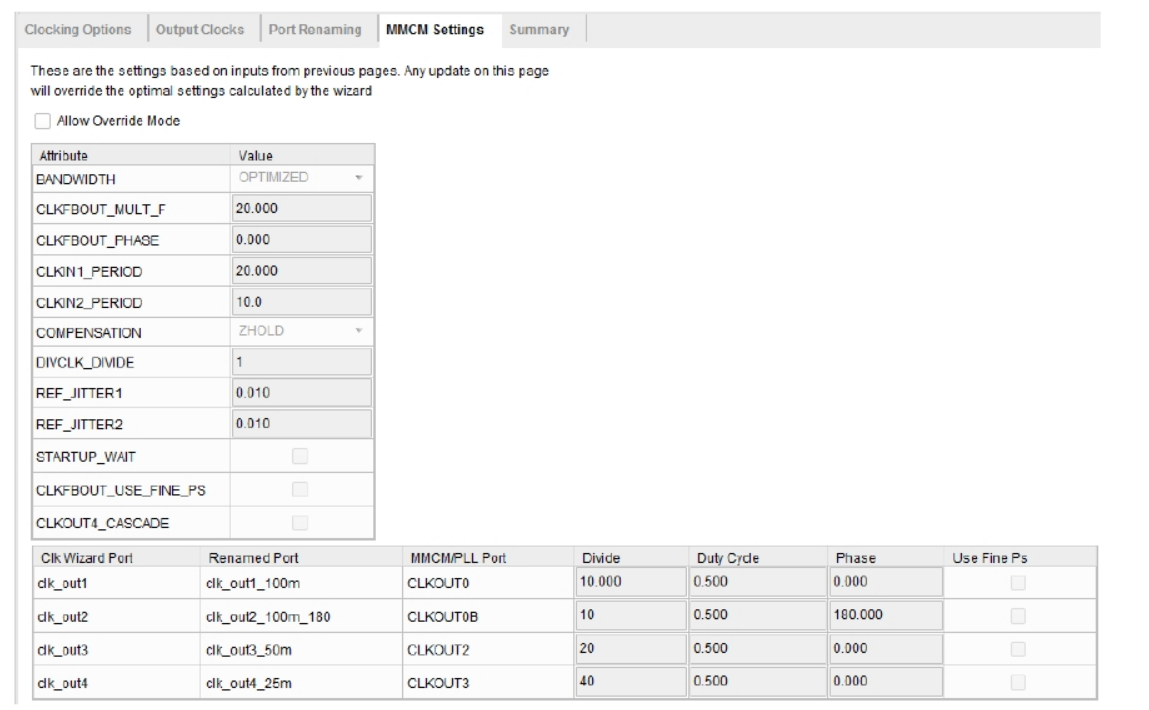
最后的“Summary”选项卡是对前面所有配置的一个总结,在这里我们直接点击“OK”按钮即可,如下图所示。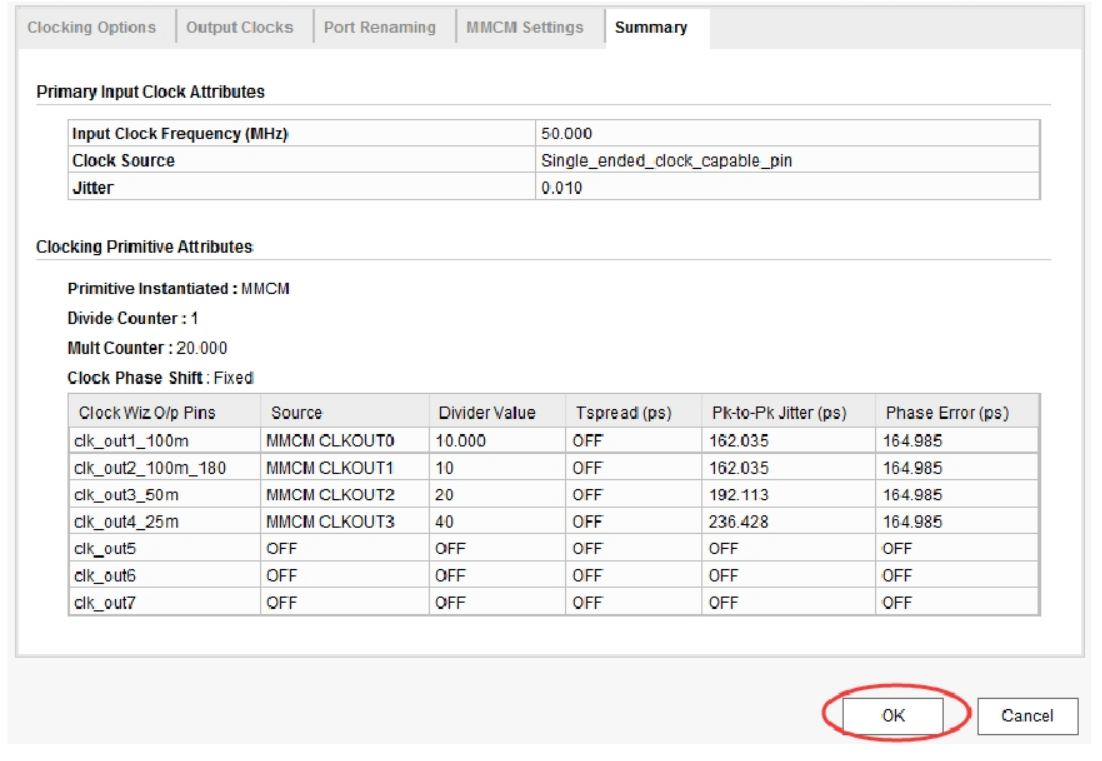
接着就弹出了“Genarate Output Products”窗口,我们直接点击“Generate”即可,如下图所示。
之后我们就可以在“Design Run”窗口的“Out-of-Context Module Runs”一栏中出现了该 IP 核对应的run“clk_wiz_0_synth_1”,其综合过程独立于顶层设计的综合,所以在我们可以看到其正在综合,如下图所示。
在其 Out-of-Context 综合的过程中,我们就可以开始编写代码了。首先打开 IP 核的例化模板,在“Source”窗口中的“IP Sources”选项卡中,依次用鼠标单击展开“IP”-“clk_wiz_0”-“Instantitation Template”,我们可以看到“clk_wiz.veo”文件,它是由 IP 核自动生成的只读的 verilog 例化模板文件,双击就可以打开它,在例化时钟 IP 核模块的时钟,可以直接从这里拷贝,如下图所示。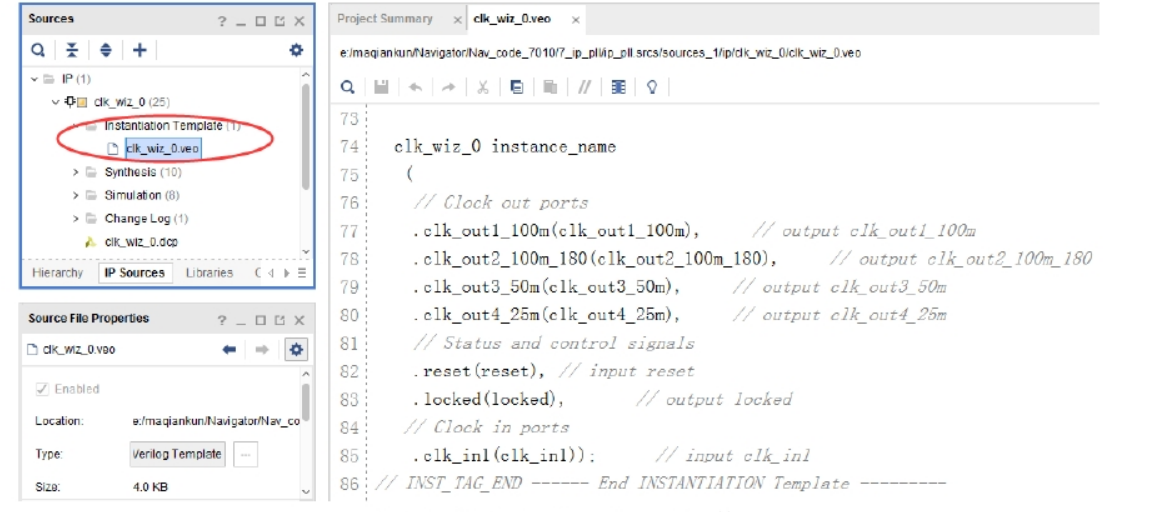
例化
module ip_clk_wiz(
input sys_clk , //系统时钟
input sys_rst_n , //系统复位,低电平有效 //输出时钟
output clk_100m , //100Mhz 时钟频率
output clk_100m_180deg, //100Mhz 时钟频率,相位偏移 180 度
output clk_50m , //50Mhz 时钟频率
output clk_25m //25Mhz 时钟频率
);
wire locked;
//MMCM/PLL IP 核的例化
clk_wiz_0 clk_wiz_0
// Clock out ports
.clk_out1_100m (clk_100m), // output clk_out1_100m
.clk_out2_100m_180 (clk_100m_180deg), // output clk_out2_100m_180
.clk_out3_50m (clk_50m), // output clk_out3_50m
.clk_out4_25m (clk_25m), // output clk_out4_25m
.reset (~sys_rst_n), // input reset
.locked (locked), // output locked
// Clock in ports
.clk_in1 (sys_clk) // input clk_in1
);
endmodule
程序中例化了 clk_wiz_0,把 FPGA 的系统时钟 50Mhz 连接到 clk_wiz_0 的 clk_in1,系统复位信号连接到 clk_wiz_0 的 reset,由于时钟 IP 核默认是高电平复位,而输入的系统复位信号 sys_rst_n 是低电平复位,因此要对系统复位信号进行取反。clk_wiz_0 输出的 4 个时钟信号直接连接到顶层端口的四个时钟输出信号。
TestBench 代码如下:

对模块进行仿真的方法这里不再赘述,仿真后得到的波形如下图所示: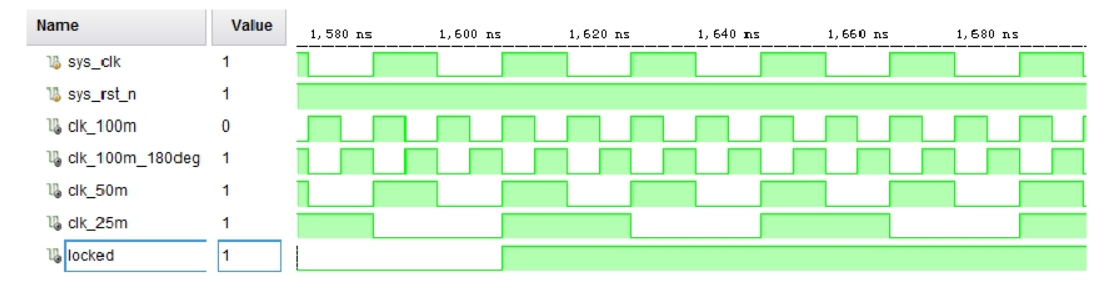
由上图可知,locked 信号拉高之后,锁相环开始输出 4 个稳定的时钟。clk_100m 和 clk_100m_180deg周期都为 10ns,即时钟频率都为 100Mhz,但两个时钟相位偏移 180 度,所以这两个时钟刚好反相;clk_50m 周期为 20ns,时钟频率为 50Mhz;clk_25m 周期为 40ns,时钟频率为 25Mhz。也就是说,我们创建的锁相环从仿真结果上来看是正确的。
RAM核
RAM 的英文全称是 Random Access Memory,即随机存取存储器,它可以随时把数据写入任一指定地址的存储单元,也可以随时从任一指定地址中读出数据,其读写速度是由时钟频率决定的。RAM 主要用来存放程序及程序执行过程中产生的中间数据、运算结果等。
Xilinx 7 系列器件具有嵌入式存储器结构,满足了设计对片上存储器的需求。嵌入式存储器结构由一列列 BRAM(块 RAM)存储器模块组成,通过对这些 BRAM 存储器模块进行配置,可以实现各种存储器的功能,例如:RAM、移位寄存器、ROM 以及 FIFO 缓冲器。Vivado 软件自带了 BMG IP 核(Block Memory Generator,块 RAM 生成器),可以配置成 RAM 或者ROM。这两者的区别是 RAM 是一种随机存取存储器,不仅仅可以存储数据,同时支持对存储的数据进行修改;而 ROM 是一种只读存储器,也就是说,在正常工作时只能读出数据,而不能写入数据。需要注意的是,配置成 RAM 或者 ROM 使用的资源都是 FPGA 内部的 BRAM,只不过配置成 ROM 时只用到了嵌入式 BRAM 的读数据端口。本章我们主要介绍通过 BRAM IP 核配置成 RAM 的使用方法。
Xilinx 7 系列器件内部的 BRAM 全部是真双端口 RAM(True Dual-Port ram,TDP),这两个端口都可以独立地对 BRAM 进行读/写。但也可以被配置成伪双端口 RAM(Simple Dual-Port ram,SDP)(有两个端口,但是其中一个只能读,另一个只能写)或单端口 RAM(只有一个端口,读/写只能通过这一个端口来进行)。单端口 RAM 只有一组数据总线、地址总线、时钟信号以及其他控制信号,而双端口 RAM 具有两组数据总线、地址总线、时钟信号以及其他控制信号。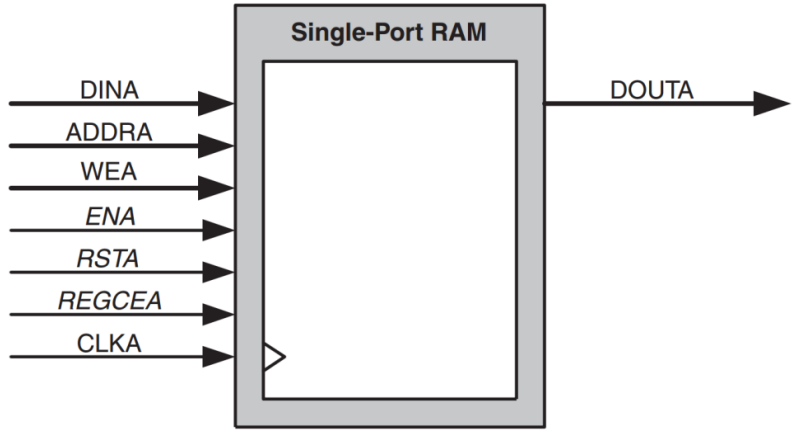
各个端口的功能描述如下:
DINA:RAM 端口 A 写数据信号。
ADDRA:RAM 端口 A 读写地址信号,对于单端口 RAM 来说,读地址和写地址共用同该地址线。
WEA:RAM 端口 A 写使能信号,高电平表示向 RAM 中写入数据,低电平表示从 RAM 中读出数据。
ENA:端口 A 的使能信号,高电平表示使能端口 A,低电平表示端口 A 被禁止,禁止后端口 A 上的读写操作都会变成无效。另外 ENA 信号是可选的,当取消该使能信号后,RAM 会一直处于有效状态。
RSTA:RAM 端口 A 复位信号,可配置成高电平或者低电平复位,该复位信号是一个可选信号。
REGCEA:RAM 端口 A 输出寄存器使能信号,当 REGCEA 为高电平时,DOUTA 保持最后一次输出的数据,REGCEA 同样是一个可选信号。
CLKA:RAM 端口 A 的时钟信号。
DOUTA:RAM 端口 A 读出的数据。
RAM核调用
具体调用方式同上,打开IP核,搜索“Block Memory”,双击“Block Memory Generator”后弹出 IP 核的配置界面,接下来对 BMG IP 核进行配置,“Basic”选项页配置界面如下图所示。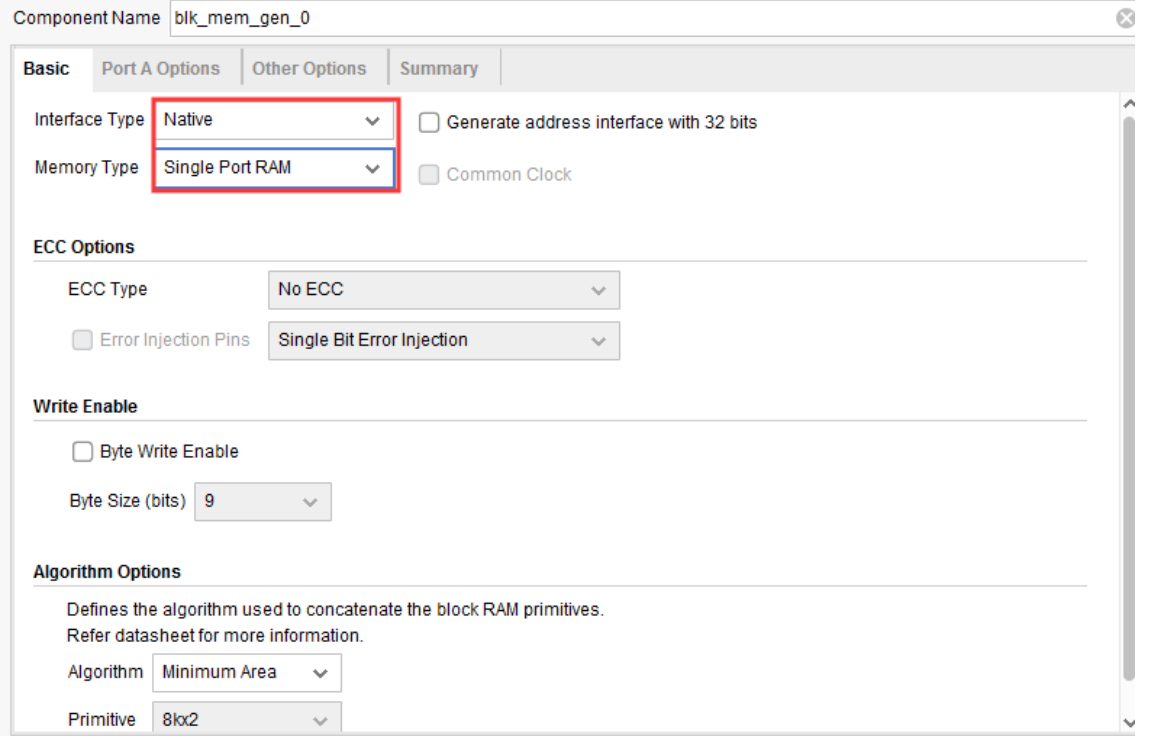
Component Name:设置该 IP 核的名称,这里保持默认即可。
Interface Type:RAM 接口总线。这里保持默认,选择 Native 接口类型(标准 RAM 接口总线);
Memory Type:存储器类型。可配置成 Single Port RAM(单端口 RAM)、Simple Dual Port RAM(伪双端口 RAM)、True Dual Port RAM(真双端口 RAM)、Single Port ROM(单端口 ROM)和 Dual Port ROM(双端口 ROM),这里选择 Single Port RAM,即配置成单端口 RAM。
ECC Options:Error Correction Capability,纠错能力选项,单端口 RAM 不支持 ECC。
Write Enable:字节写使能选项,勾中后可以单独将数据的某个字节写入 RAM 中,这里不使能。
Algorithm Options:算法选项。可选择 Minimum Area(最小面积)、Low Power(低功耗)和 Fixed Primitives(固定的原语),这里选择默认的 Minimum Area。
接下来切换至“Port A”选项页,设置端口 A 的参数,该页面配置如下: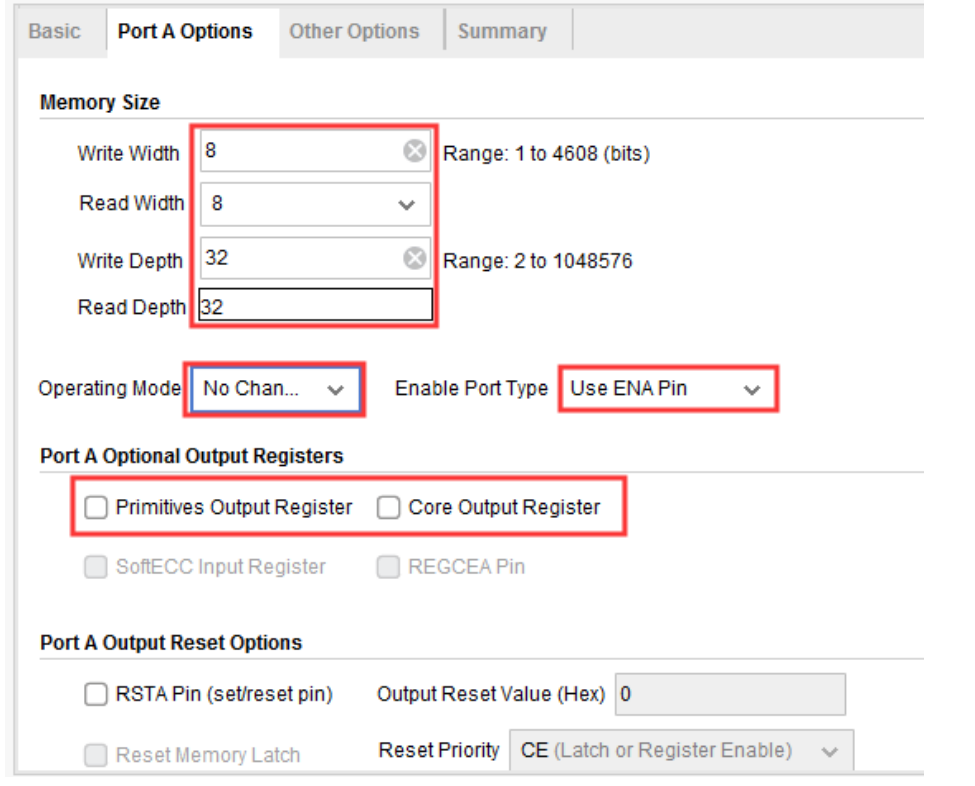
Write Width:端口 A 写数据位宽,单位 Bit,这里设置成 8。
Read Width:端口 A 读数据位宽,一般和写数据位宽保持一致,设置成 8。
Write Depth:写深度,这里设置成 32,即 RAM 所能访问的地址范围为 0-31。
Read Depth:读深度,默认和写深度保持一致。
Operating Mode:RAM 读写操作模式。共分为三种模式,分别是 Write First(写优先模式)、Read First(读优先模式)和 No Change(不变模式)。写优先模式指数据先写入 RAM 中,然后在下一个时钟输出该数据;读优先模式指数据先写入 RAM 中,同时输出 RAM 中同地址的上一次数据;不变模式指读写分开操作,不能同时进行读写,这里选择 No Change 模式。
Enable Port Type:使能端口类型。Use ENA pin(添加使能端口 A 信号);Always Enabled(取消使能信号,端口 A 一直处于使能状态),这里选择默认的 Use ENA pin。
Port A Optional Output Register:端口 A 输出寄存器选项。其中“Primitives Output Register”默认是选中状态,作用是打开 BRAM 内部位于输出数据总线之后的输出流水线寄存器,虽然在一般设计中为了改善时序性能会保持此选项的默认勾选状态,但是这会使得 BRAM 输出的数据延迟一拍,这不利于我们在Vivado 的 ILA 调试窗口中直观清晰地观察信号;而且在本实验中我们仅仅是把 BRAM 的数据输出总线连接到了 ILA 的探针端口上来进行观察,除此之外数据输出总线没有别的负载,不会带来难以满足的时序路径,因此这里取消勾选。
Port A Output Reset Options:RAM 复位信号选项,这里不添加复位信号,保持默认即可。另外,需要注意的是,下面的“Primitives Output Register”默认是选中状态的,此选项的作用是打开块 RAM 内部的位于输出数据总线之后的输出流水线寄存器,虽然在一般设计中为了改善时序性能会保持此选项的默认勾选状态,但是这会使得块 RAM 输出的数据延迟一拍,这不利于我们在 Vivado 的 ILA 调试窗口中直观清晰地观察信号;而且在本实验中我们仅仅是把块 RAM 的数据输出总线连接到了 ILA 的探针端口上来进行观察,除此之外数据输出总线没有别的负载,不会带来难以满足的时序路径。接下来的“Other Options”选项页用于设置 RAM 的初始值等,本次实验不需要设置,直接保持默认即可。
最后一个是“Summary”选项页,该页面显示了存储器的类型,消耗的 BRAM 资源等,我们直接点击“OK”按钮完成 BMG IP 核的配置,如下图所示: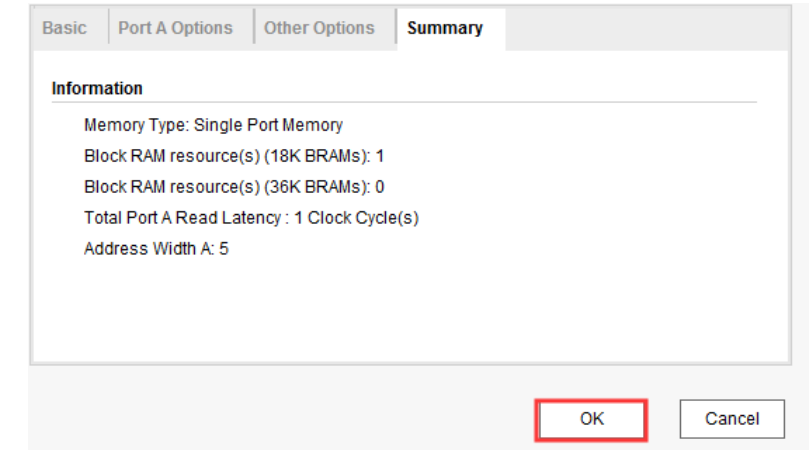
接下来会弹出询问是否在工程目录下创建存放 IP 核的文件,我们点击“OK”按钮即可。紧接着会弹出“Genarate Output Products”窗口,我们直接点击“Generate”,如下图所示。
之后我们就可以在“Design Run”窗口的“Out-of-Context Module Runs”一栏中出现了该 IP 核对应的run“blk_mem_gen_0_synth_1”,其综合过程独立于顶层设计的综合,所以在我们可以看到其正在综合,如下图所示。
在其 Out-of-Context 综合的过程中,我们就可以进行 RTL 编码了。首先打开 IP 核的例化模板,在“Source”窗口中的“IP Sources”选项卡中,依次用鼠标单击展开“IP”-“blk_mem_gen_0”-“Instantitation Template”,我们可以看到“blk_mem_gen_0.veo”文件,它是由 IP 核自动生成的只读的verilog 例化模板文件,双击就可以打开它,如下图所示。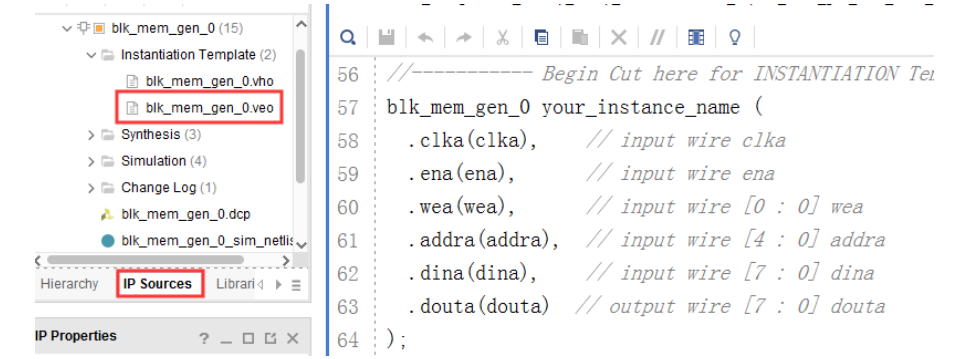
接下来我们创建一个新的设计文件,命名为 ram_rw.v,代码如下:
`timescale 1ns / 1ps
module ram_rw(
input Clk,
input Reset_n,
output ram_en,// ram使能信号
output ram_wea,//ram读写选择
output reg [4:0] ram_addr,//ram读写地址
output reg [7:0] ram_wr_data,//ram写数据
input [7:0] ram_rd_data//ram读数据
);
reg [5:0] rw_cnt; //读写控制计数器
//控制Ram使能信号
assign ram_en = Reset_n;
//rw_cnt 计数范围在 0~31,写入数据;32~63 时,读出数据
assign ram_wea = (rw_cnt <= 6'd31 && ram_en == 1'b1) ? 1'b1 : 1'b0;
//读写控制计数器,计数器范围 0~63
always @(posedge Clk or negedge Reset_n)begin
if (!Reset_n)
rw_cnt <= 1'b0;
else if(rw_cnt == 6'd63)
rw_cnt <= 1'b0;
else
rw_cnt <= rw_cnt + 1'b1;
end
//产生 RAM 写数据
always @(posedge Clk or negedge Reset_n)begin
if (!Reset_n)
ram_wr_data <= 1'b0;
else if(rw_cnt < 6'd31)
ram_wr_data <= ram_wr_data + 1'b1;
else
ram_wr_data <= 1'b0;
end
always @(posedge Clk or negedge Reset_n)begin
if (!Reset_n)
ram_addr <= 1'b0;
else if(ram_addr == 5'd31)
ram_addr <= 1'b0;
else
ram_addr <= ram_addr + 1'b1;
end
endmodule
模块中定义了一个读写控制计数器(rw_cnt),当计数范围在 031 之间时,向 ram 中写入数据;当计数范围在 3263 之间时,从 ram 中读出数据。
接下来例化创建的 RAM IP 核以及 ram_rw 模块,文件名为 ram_rw_tp.v,编写的 verilog 代码如下。
`timescale 1ns / 1ps
module ram_rw_tp(
input Clk,
input Reset_n
);
wire ram_en;// ram使能信号
wire ram_wea;//ram读写选择
wire [4:0] ram_addr;//ram读写地址
wire [7:0] ram_wr_data;//ram写数据
wire [7:0] ram_rd_data;//ram读数据
ram_rw ram_rw(
.Clk(Clk),
.Reset_n(Reset_n),
.ram_en(ram_en),// ram使能信号
.ram_wea(ram_wea),//ram读写选择
.ram_addr(ram_addr),//ram读写地址
.ram_wr_data(ram_wr_data),//ram写数据
.ram_rd_data(ram_rd_data)
);//ram读数据
blk_mem_gen_0 blk_mem_gen_0(
.clka(Clk), // input wire clka
.ena(ram_en), // input wire ena
.wea(ram_wea), // input wire [0 : 0] wea
.addra(ram_addr), // input wire [4 : 0] addra
.dina(ram_wr_data), // input wire [7 : 0] dina
.douta(ram_rd_data) // output wire [7 : 0] douta
);
endmodule
程序中例化了 ram_rw 模块和 ram IP 核 blk_mem_gen_0,其中 ram_rw 模块负责产生对 ram IP 核读/写所需的所有数据、地址以和读写使能信号,同时从 ram IP 读出的数据也连接至 ram_rw 模块。接下来对 RAM IP 核进行仿真,来验证对 RAM 的读写操作是否正确。仿真文件源代码如下:
`timescale 1ns / 1ps
module ram_rw_tb();
reg Clk;
reg Reset_n;
initial Clk = 1'b1;
always #10 Clk = !Clk;
ram_rw_tp ram_rw_tp (
.Clk(Clk),
.Reset_n(Reset_n)
);
initial begin
Reset_n = 1'b0;
#200
Reset_n = 1'b1;
end
endmodule
仿真波形
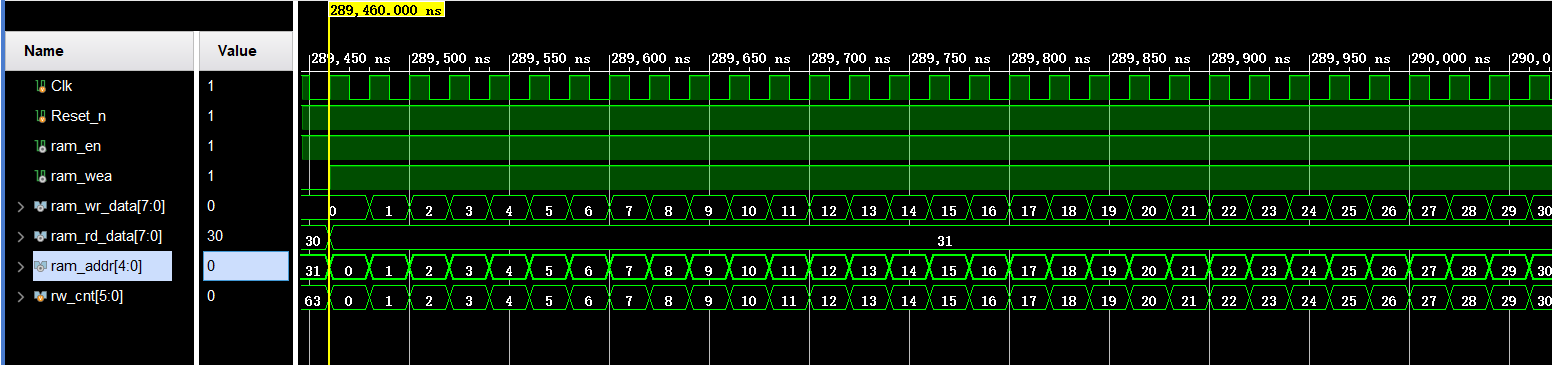
上 为 RAM 的写操作仿真波形图,由上图可知,ram_wea 信号拉高,说明此时是对 ram 进行写操作。ram_wea 信号拉高之后,地址和数据都是从 0 开始累加,也就说当 ram 地址为 0 时,写入的数据也是 0;当 ram 地址为 1 时,写入的数据也是 1,我们总共向 ram 中写入 32 个数据。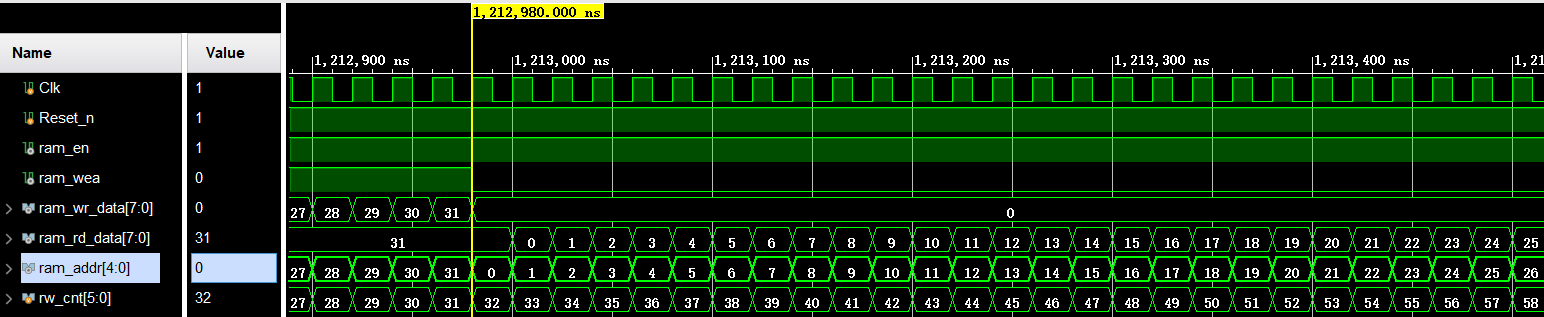
由上图可知,ram_wea 信号拉低,说明此时是对 ram 进行读操作。ram_wea 信号拉低之后,ram_addr从 0 开始增加,也就是说从 ram 的地址 0 开始读数据;ram 中读出的数据 ram_rd_data 在延时一个时钟周期之后,开始输出数据,输出的数据为 0,1,2……,和我们写入的值是相等的, 也就是说,我们创建的RAM IP 核从仿真结果上来看是正确的。
FIFO核
FIFO 的英文全称是 First In First Out,即先进先出。FPGA 使用的 FIFO 一般指的是对数据的存储具有先进先出特性的一个缓存器,常被用于数据的缓存,或者高速异步数据的交互也即所谓的跨时钟域信号传递。它与 FPGA 内部的 RAM 和 ROM 的区别是没有外部读写地址线,采取顺序写入数据,顺序读出数据的方式,使用起来简单方便,由此带来的缺点就是不能像 RAM 和 ROM 那样可以由地址线决定读取或写入某个指定的地址。
根据 FIFO 工作的时钟域,可以将 FIFO 分为同步 FIFO 和异步 FIFO。同步 FIFO 是指读时钟和写时钟为同一个时钟,在时钟沿来临时同时发生读写操作。异步 FIFO 是指读写时钟不一致,读写时钟是互相独立的。Xilinx 的 FIFO IP 核可以被配置为同步 FIFO 或异步 FIFO,其信号框图如下图所示。从图中可以了解到,当被配置为同步 FIFO 时,只使用 wr_clk,所有的输入输出信号都同步于 wr_clk 信号。而当被配置为异步 FIFO 时,写端口和读端口分别有独立的时钟,所有与写相关的信号都是同步于写时钟 wr_clk,所有与读相关的信号都是同步于读时钟 rd_clk。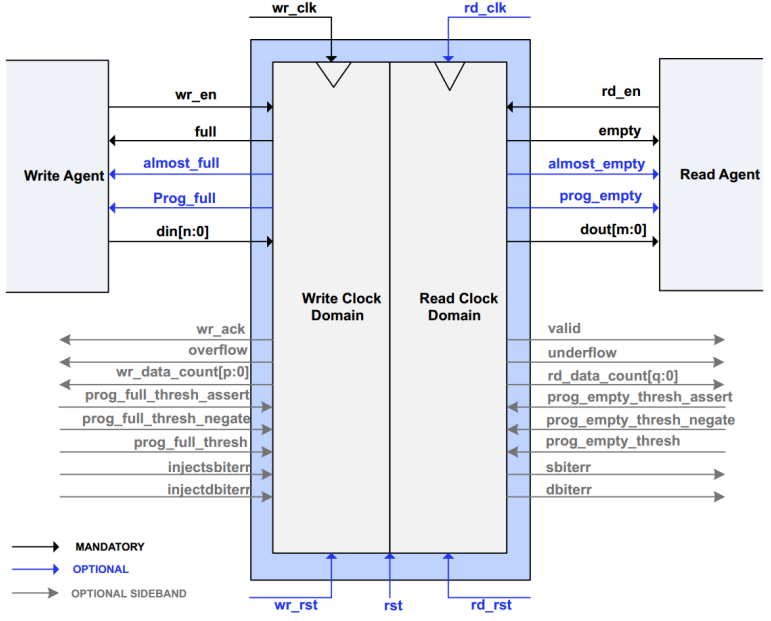
对于 FIFO 需要了解一些常见参数:
FIFO 的宽度:FIFO 一次读写操作的数据位 N。
FIFO 的深度:FIFO 可以存储多少个宽度为 N 位的数据。
将空标志:almost_empty。FIFO 即将被读空。
空标志:empty。FIFO 已空时由 FIFO 的状态电路送出的一个信号,以阻止 FIFO 的读操作继续从FIFO 中读出数据而造成无效数据的读出。
将满标志:almost_full。FIFO 即将被写满。
满标志:full。FIFO 已满或将要写满时由 FIFO 的状态电路送出的一个信号,以阻止 FIFO 的写操作继续向 FIFO 中写数据而造成溢出。
读时钟:读 FIFO 时所遵循的时钟,在每个时钟的上升沿触发。
写时钟:写 FIFO 时所遵循的时钟,在每个时钟的上升沿触发。
这里请注意,“almost_empty”和“almost_full”这两个信号分别被看作“empty”和“full”的警告信号,他们相对于真正的空(empty)和满(full)都会提前一个时钟周期拉高。
之所以有同步 FIFO 和异步 FIFO 是因为各自的作用不同。同步 FIFO 常用于同步时钟的数据缓存,异步 FIFO 常用于跨时钟域的数据信号的传递,例如时钟域 A 下的数据 data1 传递给异步时钟域 B,当 data1 为连续变化信号时,如果直接传递给时钟域 B 则可能会导致收非所送的情况,即在采集过程中会出现包括亚稳态问题在内的一系列问题,使用异步 FIFO 能够将不同时钟域中的数据同步到所需的时钟域中。
FIFO核调用
同上,首先创建一个名为 ip_fifo 的工程,接下来我们创建 fifo IP 核。在 Vivado 软件的左侧“Flow Navigator”栏中单击“IP Catalog”,在“IP Catalog”窗口中,在搜索栏中输入“fifo”关键字,这时 Vivado 会自动查找出与关键字匹配的IP核名称,我们双击“FIFO Generator”,弹出“Customize IP”窗口,如下图所示。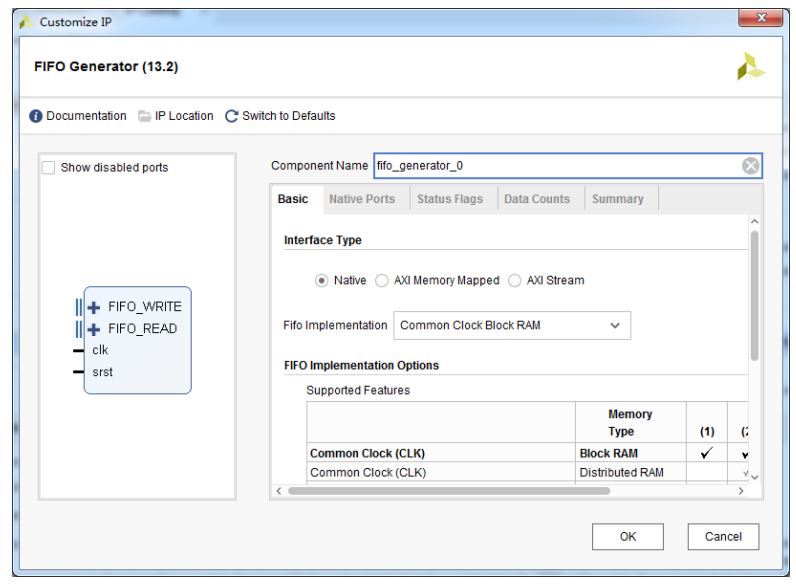
接下来就是配置 IP 核的时钟参数的过程。最上面的“Component Name”一栏设置该 IP 元件的名称,这里保持默认即可。在第一个“Basic”选项
卡中,“Interface Type”选项用于选择 FIFO 接口的类型,这里我们选择默认的“Native”,即传统意义上的FIFO 接口。“Fifo Implementation”选项用于选择我们想要实现的是同步 FIFO 还是异步 FIFO 以及使用哪种资源实现 FIFO,这里我们选择“Independent Clocks Block RAM”,即使用块 RAM 来实现的异步 FIFO。如下图所示。
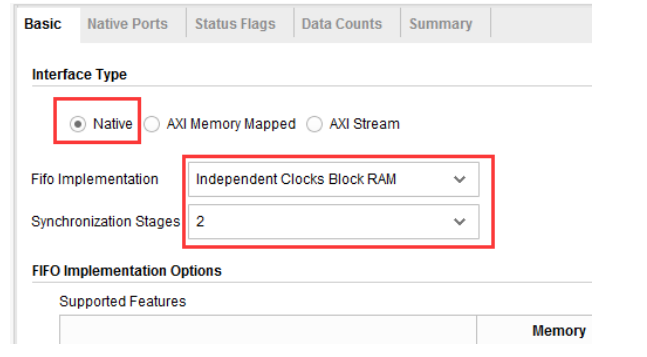
接下来是“Native Ports”选项卡,用于设置 FIFO 端口的参数。“Read Mode”选项用于设置读 FIFO时的读模式,这里我们选择默认的“Standard FIFO”。“Data Port Parameters”一栏用于设置读写端口的数据总线的宽度以及 FIFO 的深度,写宽度“Write Width”我们设置为 8 位,写深度“Write Depth”我们设置为 256,注意此时 FIFO IP 核所能实现的实际深度却是 255;虽然读宽度“Read Width”能够设置成和写宽度不一样的位宽,且此时读深度“Read Depth”会根据上面三个参数被动地自动设置成相应的值;但是我们还是将读宽度“Read Width”设置成和写宽度“Write Width”一样的位宽,这也是在实际应用中最常用的情况。由于我们只是观察 FIFO 的读写,所以最下面的“Reset Pin”选项我们可以不使用,把它取消勾选。其他设置保持默认即可,如下图所示。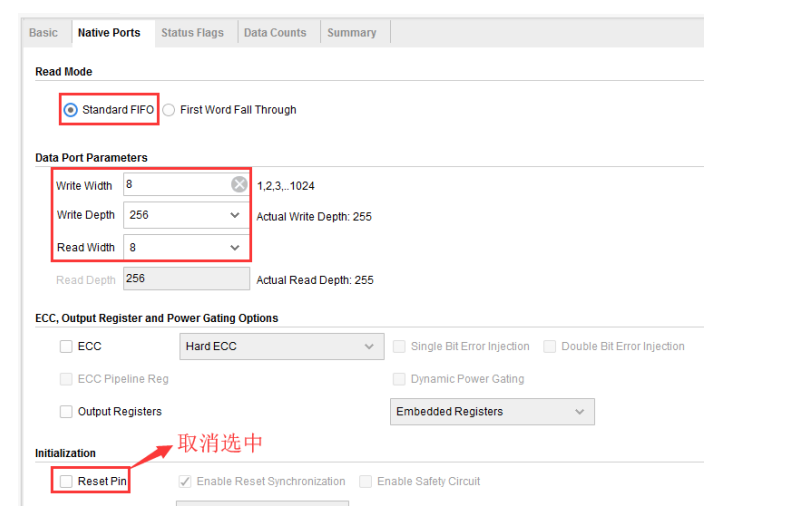
“Status Flags”选项卡,用于设置用户自定义接口或者用于设定专用的输入口。这里我们使用“即将写满”和“即将读空”这两个信号,所以我们把它们勾选上,其他保持默认即可,如下图所示。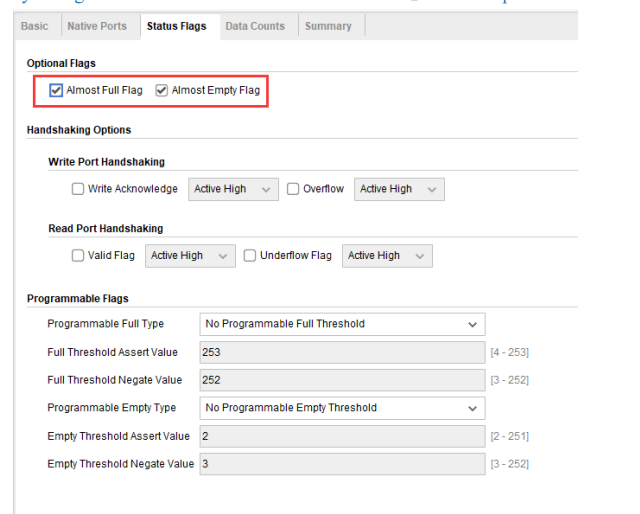
“Data Counts”选项卡用于设置 FIFO 内数据计数的输出信号,此信号表示当前在 FIFO 内存在多少个有效数据。为了更加方便地观察读/写过程,这里我们把读/写端口的数据计数都打开,且计数值总线的位宽设置为满位宽,即 8 位,如下图所示。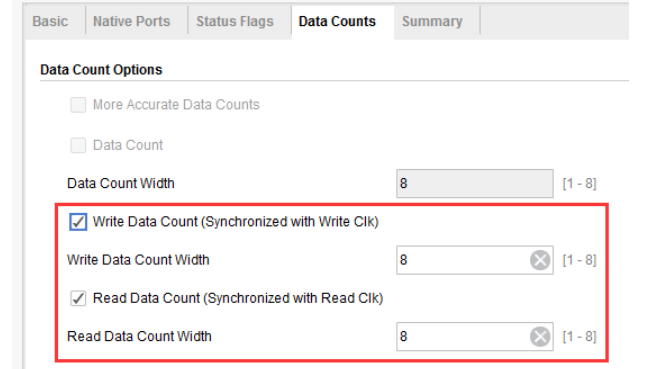
最后的“Summary”选项卡是对前面所有配置的一个总结,在这里我们直接点击“OK”按钮即可。接着就弹出了“Genarate Output Products”窗口,我们直接点击“Generate”即可。
在其 Out-of-Context 综合的过程中,我们就可以进行 RTL 编码了。首先打开 IP 核的例化模板,在“Source”窗口中的“IP Sources”选项卡中,依次用鼠标单击展开“IP”-“fifo_generator _0”-“Instantitation Template”,我们可以看到“fifo_generator_0.veo”文件,它是由 IP 核自动生成的只读的verilog 例化模板文件,双击就可以打开它。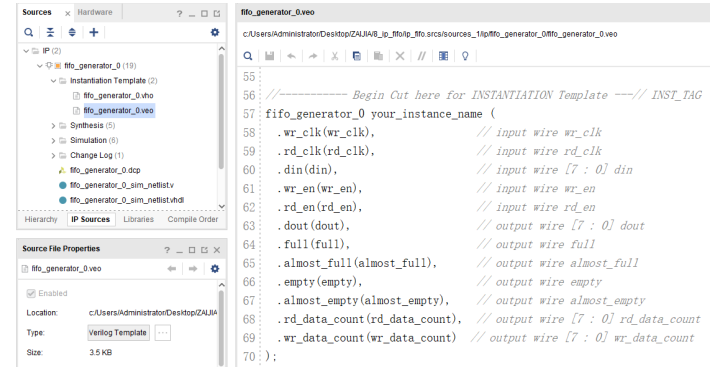
我们创建一个 verilog 源文件,其名称为 fifo_tp.v,作为顶层模块,其代码如下:
module fifo_tp(
input Clk,
input Reset_n,
);
wire fifo_wr_en ;//FIFO核写使能
wire fifo_rd_en ;//FIFO核读使能
wire [7:0] fifo_din;//写入到FIFO的数据
wire [7:0] fifo_dout;//从FIFO读出的数据
wire almost_full;//FIFO将满信号
wire almost_empty;//FIFO将空信号
wire fifo_full;//FIFO满信号
wire fifo_empty;//FIFO空信号
wire [7:0] fifo_wr_data_count;//FIFO写时钟域的数据计数
wire [7:0] fifo_rd_data_count;//FIFO读时钟域的数据计数
fifo_generator_0 fifo_generator_0 (
.wr_clk(Clk), // input wire wr_clk
.rd_clk(Clk), // input wire rd_clk
.din(fifo_din), // input wire [7 : 0] din
.wr_en(fifo_wr_en), // input wire wr_en
.rd_en(fifo_rd_en), // input wire rd_en
.dout(fifo_dout), // output wire [7 : 0] dout
.full(fifo_full), // output wire full
.almost_full(almost_full), // output wire almost_full
.empty(fifo_empty), // output wire empty
.almost_empty(almost_empty), // output wire almost_empty
.rd_data_count(fifo_rd_data_count), // output wire [7 : 0] rd_data_count
.wr_data_count(fifo_wr_data_count) // output wire [7 : 0] wr_data_count
);
fifo_wr fifo_wr(
.Clk(Clk),
.Reset_n(Reset_n),
.almost_empty(almost_empty),
.almost_full(almost_full),
.fifo_wr_en(fifo_wr_en),
.fifo_wr_data(fifo_din)
);
fifo_rd fifo_rd(
.Clk(Clk),
.Reset_n(Reset_n),
.almost_empty(almost_empty),
.almost_full(almost_full),
.fifo_rd_en(fifo_rd_en),
.fifo_rd_data(fifo_dout)
);
endmodule
顶层模块主要是对 FIFO IP 核、写 FIFO 模块、读 FIFO 模块进行例化。
写 FIFO 模块 fifo_wr.v 源文件的代码如下:
module fifo_wr(
input Clk,
input Reset_n,
input almost_empty,
input almost_full,
output reg fifo_wr_en,
output reg [7:0]fifo_wr_data
);
reg [1:0]state; //动作状态
reg almost_empty_d0; //almost_empty延迟一拍
reg almost_empty_syn;//almost_empty延迟两拍
reg [3:0] dly_cnt;//延迟计数器
always@(posedge Clk or negedge Reset_n)begin
if(!Reset_n)begin
almost_empty_d0 <= 1'b0;
almost_empty_syn <= 1'b0;
end
else begin
almost_empty_d0 <= almost_empty;
almost_empty_syn <= almost_empty_d0;
end
end
always@(posedge Clk or negedge Reset_n)begin
if(!Reset_n)begin
fifo_wr_en <= 1'b0;
fifo_wr_data <= 8'd0;
state <= 2'd0;
dly_cnt <= 4'd0;
end
else begin
case(state)
2'd0:begin
if(almost_empty_syn)begin //如果检测到FIFO将被读空,下一拍就会空,下下拍进入延时状态
state <= 2'd1;
end
else
state <= state;
end
2'd1:begin
if(dly_cnt == 4'd10)begin //延迟10拍 ,原因是FIFO IP核内部信号的更新存在延时,延迟10拍等待状态信号更新完毕
dly_cnt <= 4'd0;
state <= 2'd2; //开始写操作
fifo_wr_en <= 1'b1; //打开写使能
end
else
dly_cnt <= dly_cnt +4'd1;
end
2'd2:begin
if(almost_full)begin //等待FIFO将被写满,下一拍就会满
fifo_wr_en <= 1'b0; //关闭写使能
fifo_wr_data <= 8'd0;
state <= 2'd0; //回到第一个状态
end
else begin
fifo_wr_en <= 1'b1; //如果没有写满,持续打开写使能
fifo_wr_data <= fifo_wr_data + 1'd1;
end
end
default :state <= 2'd0;
endcase
end
end
endmodule
fifo_wr 模块的核心部分是一个不断进行状态循环的小状态机,如果检测到 FIFO 为空,则先延时 10拍,这里注意,由于 FIFO 的内部信号的更新比实际的数据读/写操作有所延时,所以延时 10 拍的目的是等待 FIFO 的空/满状态信号、数据计数信号等信号的更新完毕之后再进行 FIFO 写操作,如果写满,则回到状态 0,即等待 FIFO 被读空,以进行下一轮的写操作。
读 FIFO 模块 fifo_rd.v 源文件的代码如下:
module fifo_rd(
input Clk,
input Reset_n,
input [7:0] fifo_dout,
input almost_full,
input almost_empty,
output reg fifo_rd_en
);
reg [1:0] state ;
reg almost_full_d0;
reg almost_full_syn;
reg [3:0] dly_cnt;
always@(posedge Clk or negedge Reset_n)begin
if(!Reset_n)begin
almost_full_d0 <= 1'b0;
almost_full_syn <= 1'b0;
end
else begin
almost_full_d0 <= almost_full;
almost_full_syn <= almost_full_d0;
end
end
always@(posedge Clk or negedge Reset_n)begin
if(!Reset_n)begin
fifo_rd_en <= 1'b0;
state <=2'd0;
dly_cnt <= 4'd0;
end
else begin
case(state)
2'd0:begin
if(almost_full_syn)
state <= 2'd1;
else
state <= state;
end
2'd1:begin
if(dly_cnt == 4'd10)begin
dly_cnt <= 4'd0;
state <= 2'd2;
end
else
dly_cnt<= dly_cnt +4'd1;
end
2'd2:begin
if(almost_empty)begin
fifo_rd_en <= 1'b0;
state <= 2'd0;
end
else
fifo_rd_en <= 1'b1;
end
defaul:state <= 2'd0;
endcase
end
end
读模块的代码结构与写模块几乎一样,也是使用一个不断进行状态循环的小的状态机来控制操作过程。