该篇为初学时,在阅读李航老师的《统计学习方法中》进行的一些摘录。主要是介绍机器学习的一些基本概念。
机器学习
1.特点
- 计算机为平台
- 数据为研究对象
- 对数据预测与分析为目的
- 以方法为中心,构建模型并应用模型进行预测与分析
- 概率论、统计学、计算理论、最优化理论及计算机科学多学科交叉
2.思想
从数据出发找到他们的特征,从而抽象出模型,发现数据中的知识,最后回到对数据的分析与预测中去。这些数据包括(有些数据是可以吃的):
- 数字
- 文字
- 图像
- 视频
- 音频
3.方法
- 监督学习(supervised learning)
指对数据的若干特征与若干标签(类型)之间的==关联性==进行建模的过程; 只要模型被确定,就可以应用到新的未知数据上。
这类学习过程可以进一步分为「分类」(classification)任务和「回归」(regression)任务。
在分类任务中,标签都是离散值;
而在回归任务中,标签都是连续值。
非监督学习(unsupervised learning)
指对不带任何标签的数据特征进行建模,通常被看成是一种“==让数据自己介绍自己==” 的过程。
这类模型包括「聚类」(clustering)任务和「降维」(dimensionality reduction)任务。
聚类算法可以将数据分成不同的组别,而降维算法追求用更简洁的方式表现数据。半监督学习(semi-supervised learning)
另外,还有一种半监督学习(semi-supervised learning)方法,介于有监督学习和无监督学习之间。通常可以在数据不完整时使用。
强化学习(reinforcement learning)
强化学习不同于监督学习,它将学习看作是试探评价过程,以”试错” 的方式进行学习,并与环境进行交互已获得奖惩指导行为,以其作为评价。 此时系统靠自身的状态和动作进行学习,从而改进行动方案以适应环境。
(提示:半监督学习和强化学习比较偏向于深度学习)
4.类型
分类问题
监督学习从数据中学习一个分类决策函数或分类模型,称为分类器(classifier)。分类器对新的输入进行输出的预测,这个过程称为分类。
标注问题
标注问题也是一个监督学习问题。可以认为标记问题是分类问题的一个推广。
标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。也就是说,分类问题的输出是一个值,而标注问题输出是一个向量,向量的每个值属于
一种标记类型。回归问题
回归模型正是表示从输入变量到输出变量之间映射的函数。回归问题的学习等价于函数拟合:选择一条函数曲线,使其很好地拟合已知数据且很好地预测未知数据
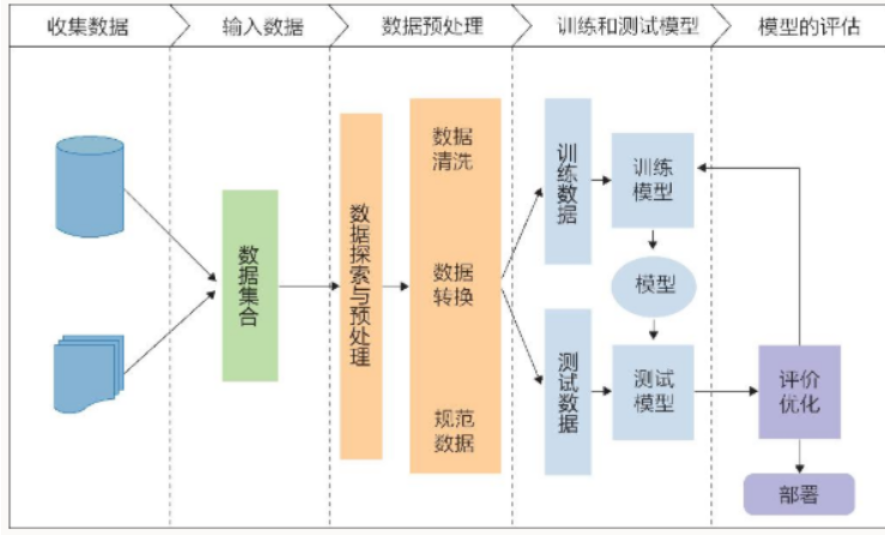
5.步骤
三要素:模型(model) 策略(strategy) 算法(algorithm)
数据和特征决定了机器学习的上界,而模型和算法只是去逼近这个上界。步骤为:
- 得到一个有限的训练数据集合;
- 确定包含所有可能的模型的假设空间(学习模型的集合);
- 确定模型选择的准则(学习的策略);
- 实现求解最优模型的算法,即学习的算法;
- 通过学习方法选择最优模型;
- 利用学习的最优模型对新数据进行预测或分析。
深度学习其实也是使用的这种步骤,机器学习可以说是深度学习的总称。只是特征提取的方式不同。简单提一下,这里的模型其实可以类比于一些模型比如CNN等。策略是损失函数。算法是如何使得模型得到最优解的方法。